With Cassandra and OpenSearch clusters split across two sites, is there a way of having the DMA’s talk to the nodes on the same site as them for the main connection, and the other site as a secondary connection?
Is it just the order in the xml tag, or do they cycle through them etc?
Hi Philip,
If I remember correctly, the Cassandra implementation in DM is using the DCAwareRoundRobinPolicy, it will basically detect the closest DC automatically and use all nodes of that DC in a round robin mechanism to load balance.
As far as I know, it will not automatically failover to the other DC. When all Cassandra nodes in a DC are down, you will need a restart of DM to have DM connect to the other DC. The reasoning behind this, is if all nodes in a DC are down, most likely something is also happening with the DM node in that DC. Also see this great writeup here: https://foundev.medium.com/cassandra-local-quorum-should-stay-local-c174d555cc57
Between our two main DC’s that Cassandra and OpenSearch will be in there’s a big enough wan link with only 2ms latency, so most of the issues raised on that article wouldn’t count for us.
We have one outlier on and DMA pair that’s not in either of those DC’s, which has a 10ms latency.
Hi Philip,
I this scenario it’s the driver middleware to Cassandra which does not allow for an automatic connection to another DC in case all local nodes are unavailable.
The idea being that if all nodes in a DC are unavailable then the DataMiner agents in said DC are likely down as well.
There are upcoming improvements to the behaviour of connecting to Cassandra nodes that will be tentatively released with the 10.3.11.
This will allow you to specify for each DataMiner agent which DB nodes should be tried first. With this it will be possible to have a failover pair spanning 2 datacenters in which each agent of the pair only connects to its local DC.
Hi Philip,
In High-level and configuration wise what I have seen so far:
Cassandra, each site will be an datacenter and all nodes should share same “cassandra.yaml” , in each agent db.xml you can then configure “local” Cassandra IP Addresses.
OpenSearch, it´s possible that the online DMA always tries to read first from the ‘local’ Elastic cluster, by configuring the priorityOrder from the DBConfiguration.xml file, this is DMA specific. The lowest priority order will always be picked first. So, just set your local DMA´s with the lowest priority order. 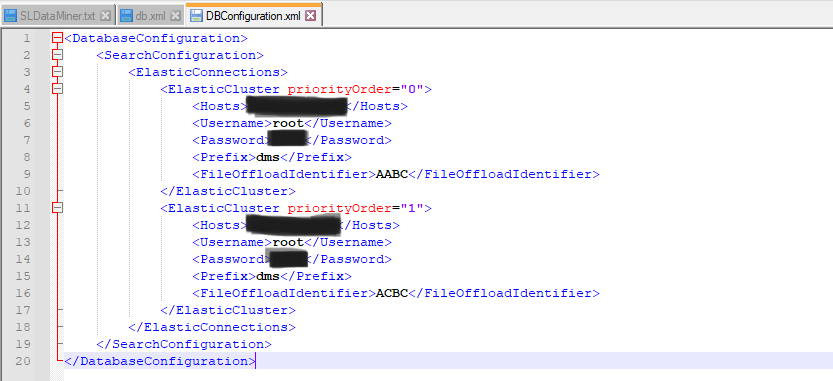
Hi Sergio,
They’re single Cassandra and OpenSearch clusters across two datacentres that we’ll want to use swarming on.
For resilience on the clusters we’d want the local datacentre nodes for each to be used as default, then the other datacentre if the local nodes go down.
The PriorityOrder on the ElasticSearch page is for multiple clusters, rather than a single cluster spanning two DCs, with the general pages for both not suggesting any option on preferred nodes in either cluster.
For Cassandra, you should configure the datacenters in Cassandra as in reality. Spreading your nodes over multiple datacenters, but having them configured as one datacenter in Cassandra is not the best practice. Only once you have the two DC in Cassandra, we can make use of DCAwareRoundRobin to execute queries on the DB and keep the queries to one datacenter. In addition, DCAwareRoundRobin is scheduled to be released in DM 10.3.10 ATM.
Thanks Michiel,
The cluster is being configured with the DC they’re in set on each node.
Is the default round robin policy used currently if DCAwareRoundRobin isn’t available until 10.3.10?
Will the UsedHostsPerRemoteDc be used in the implementation, to allow connection to the remote DC if none of the nodes in the local DC are available?
Hi Philip,
The UsedHostsPerRemoteDC is deprecated in the Cassandra driver and won’t be used, Mathijs has linked the blog post of the Cassandra community as to their reasoning on this.
Currently the DCAwareRoundRobinPolicy is used, but it’s not possible to specify the DB nodes to contact first in the DB.xml as this information is synced in the cluster. Tentatively, this will be possible with the 10.3.11 release.
As for OpenSearch, by default each node has the coordinating role assigned to it, allowing it to handle client requests. For a single cluster the DataMiner agent will connect to the address listed in its DB.xml configuration. This address is used as an initial contact point but from that point onwards the queries can be sent to any node with the coordinating role. Currently it’s not supported to limit this traffic to a specific node with a setting in DataMiner.
Hi Matthijs,
Thanks, will it automatically use another DC in the scenario that all the local nodes are unavailable?