Continuing our series on our CI-CD journey, this episode deals with the choices and tools selection we’ve made in our continuous integration for our software development teams, and how we’ve tried to align system deployment and core development teams, both procedurally and technologically. This is part of the recognition that all teams are ultimately delivering value to our users, just at different points in the pipeline.
This goal here is to show how the choices we’ve made to suit our operations. Different decisions may suit your particular situation.
- Set your goals
- Define your process
- Choose your tech
Code Storage & Version Control
Upon deciding to commit to a rationalization & standardization of our tools, we acknowledged immediately that we had a disparity in version control systems. Our system engineering teams working on communication protocol drivers and solutions were using SVN, whereas our core software teams were using GIT.
This disparity was a hangover from some necessary decisions made quite some years ago, in order to switch our core software team to GIT from SourceSafe due to that tool’s discontinuation. At the time, GIT was chosen because of the flexibility in branching and ease of support for multiple developer cooperation on code.
Approaching this afresh, we recognized that system engineering teams were increasingly moving to architecturally complex development, and GIT was increasingly more and more of a match. Speed of code commits to GIT also helped to solidify our decision. We have an already large and still growing population of development teams operating globally, so fluidity and efficiency are key.
An overarching requirement for CI-CD was the ability to collaborate easily with multiple developers and teams, both inside and outside of our organization. GIT seemed to be a logical match to tie in with GITHUB, which is a widely recognized, popular cloud-based software development host.

We have adopted over the years an increasingly strict approach to code review and testing. Back in the dim and distant past, we can imagine a time where code review was not always mandatory and initial. QA, such as unit testing, might not happen until the commit was already firmly in the codebase for some time, and could even sometimes be forgotten.
One can shout from the rooftops and evangelize on these subjects as much as one wants, but the best way to enforce the appropriate and necessary procedure is to make it impossible to do anything else. For us putting Gerrit in front of GIT was the answer to this, albeit a heavily customized implementation in our case.
This enables us to have two layers of approval before any code can hit any of our main core branches or solutions.
- Code review and approval by a senior developer
- QA review, which includes perhaps an isolated manual test of a feature and/or a unit test. Unit tests and other types of automated test also have their own approval procedures managed in Gerrit and reside in related GIT repositories
Notwithstanding, any end-to-end testing and other extended testing that can occur in the context of an entire codebase, we already have a solid qualitative grounding at the code committal stage, which is driven automatically. This way, it feels part of the necessary process rather than some barrier one must hurdle, or worse, still ignore or forget.
Pipeline Automation
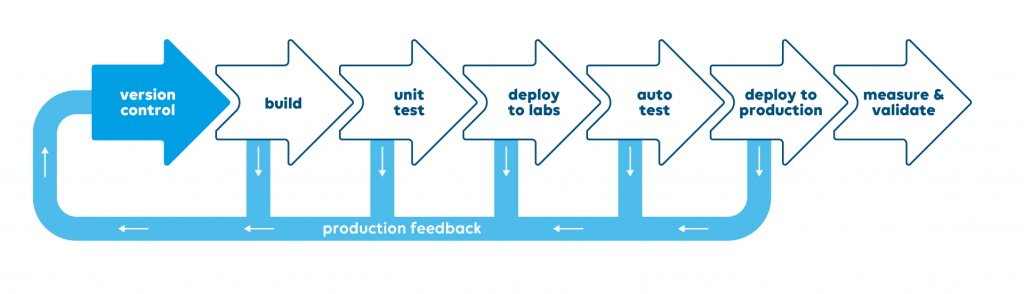
The tool chosen for automation of our pipelines perhaps seems the most obvious. Jenkins is a well-established automation server and has great flexibility. You can plug almost anything you want into it, both generic and bespoke. It also has a great ease of use, masses of online documentation and examples.
We also must admit to a company legacy in Jenkins that has been present in isolation for a while. Sometimes, a legacy that we don’t want to get rid of is a bad thing in terms of a “it ain’t broke, so don’t fix it”attitude. But in this case, Jenkins has served us well.
Jenkins has allowed us to coordinate and automate very complicated built processes in both our core software, and increasingly, in our system deployment operations, and to easily apply quality gates effectively.
It’s true that there are ‘other kids on the block’ on this topic and one must consider if some of these tools are more suitable in terms of cloud operations particularly. However, other major players such as Azure DevOps support the integration of Jenkins pipelines in their architecture, so we can be certain of being future proof with Jenkins.
Having said all the above, it’s also worth noting at the time of writing we are also working natively with Azure DevOps for our Cloud Connected agents feature. (You can learn more about this feature in this blog article.
More on Quality Gates
One of the key primary drivers for continuous integration through automation is automated quality gates. These gates can come at various stages:
- On build – To prevent errant code even being built, you will want to leverage unit testing as much as possible to save time and money. Ideally, unit tests are the basis of your initial development in the first place, so that everything you do conforms to the requirements behind the unit test. You can also perform mutation analysis through mock objects to see how your code units deal with erroneous input.
For an in-depth view on unit testing, see this great series by Jan Staelens and Pedro Debevere on unit testing for DataMiner Protocol Development.
- Static Code analysis – Here, we use a combination of approaches and tools.
- On build – SonarQube allows all relevant checks to be run on a given C# codebase such as a protocol driver
- In development – SonarLint can be run as required during code development
- DIS Validator – Skyline has developed its own code analysis tool specific to the development structure of drivers concentrating on the XML content. To learn more about the Validator and DataMiner Integration Studio (DIS), why not take the free course? Crucially, we can run this both at development time and as part of the commit process
Hopefully, this post has given you some insight into our technical choices and it can help with your future decisions, particularly where you are involved in development with DataMiner.