Hi Dojo – question for all the SL-processes experts – 50 points for a good answer (;
We spotted a memory leak on SLDataGateway in 10.2.4.0-11608: the memory consumption can run up to 20GB (sometimes even beyond).
Our squad has already confirmed the issue is addressed in 10.2.10 – plans for the upgrade are already shared – but regardless of the fix, I’m curious about how this started – what could be the root cause of this behaviour?
It started on a few servers on the same date – could there be any possible relation with NIC teaming settings on the servers (e.g. increased MTU size)? Any relation to be checked with SLElement (or SLProtocol)?
If not, what else could we check to mitigate the impact until the upgrade is performed?
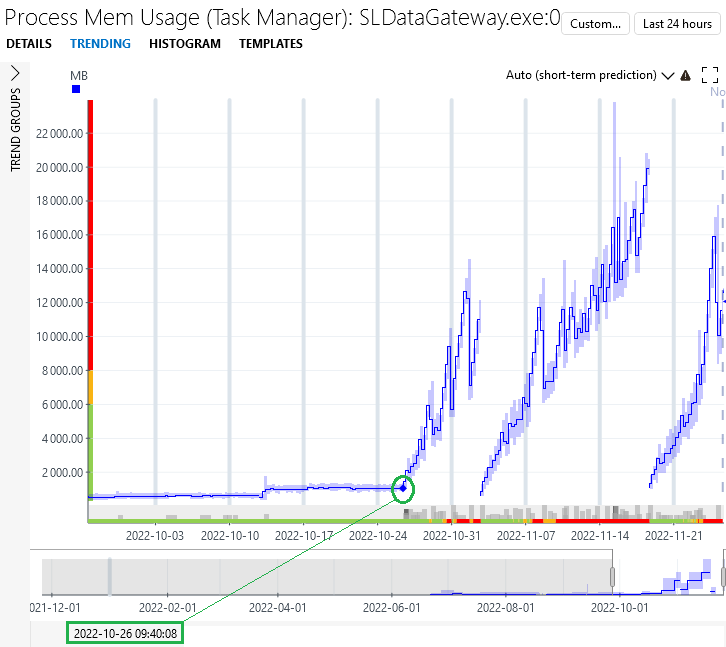
The behaviour was first observed last month – the process was using less than 1GB before:
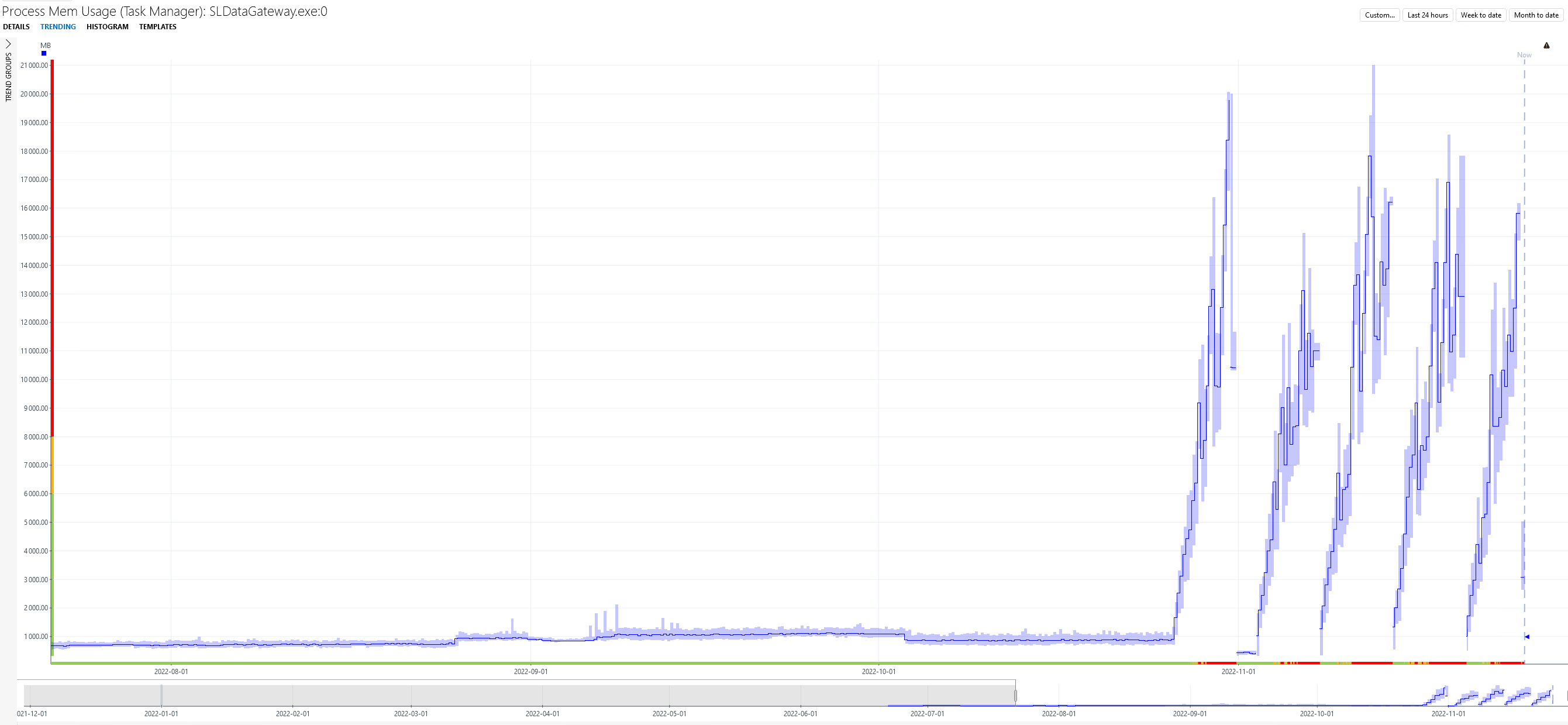
Thanks
Hi Alberto,
Between the 10.2.4.0 and the 10.2.10.0 feature release there have been quite a few improvements to memory handling in SLDataGateway.
A few of those resolved situations in which memory would leak, those did all stem from race conditions that would be nearly impossible to mitigate.
This could also be a build up of memory on the queues. That is something where the MTU size on the NIC teaming could have an effect if it’s throttling access to the DB. But that seems like a long shot. Was the NIC teaming changed around the time that this started occurring?
I would recommend checking out the information events from around when this issue started occurring. As those may indicate a change that may be the root cause of this (new version? protocol upgrade? more elements? …)
Thanks for your feedback, Simon
Indeed we’ve already checked the info events at OS layer – the same operations were performed in different environments – but only one has shown this effect.
I was hoping that a memory dump could help in better analysing the cause within the application itself – as this seems to manifest only where the element load is significant – however if the excessive memory consumption has been addressed in multiple parts of SLDataGateway, it would be an excessive effort to debug now. Will upgrade and observe the effects in 10.2.10
NIC wise, an increase in MTU size (jumbo frames) was identified as a prerequisite to process real-time data with specific protocols, but this isn’t something configured by default – normally a DMA operates with the standard Windows settings (standard MTU size), so I’m keen to find out more about the additional checks (if any) when switching from 1500 to 9000 bytes at NIC level.
Actually, this might be a separate specific question – I’ll raise it now
and will report back here on SLDataGateway after the upgrade.
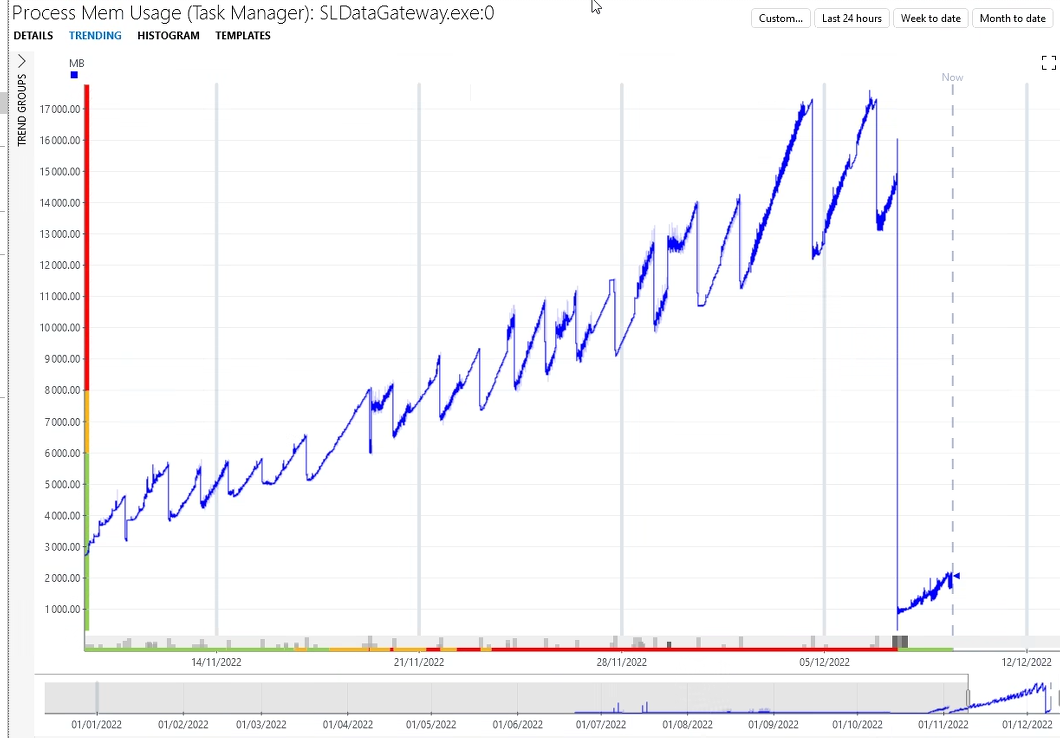
Simon, quickly adding a screenshot below – can confirm the slope is much better with 10.2.10, yet it’s still present – any chance some sys-dev could take a look into this if the trend keeps showing an increased memory usage over time?
Sharing the memory trend for SLDataGateway after the upgrade to 10.2.10
The slope seems more tolerable, yet it’s still present:
Hi Alberto, is it possible that you are using CassandraCluster (see DB.Xml for Cassandra configuration)? In that case the saw pattern memory leak will be fixed from 10.3.1 onwards.
Thanks for the hint Jens – no Cassandra cluster in this environment.
We run a local Cassandra DB on each agent – any additional check we could perform?
Not sure if this still applies – but any difference in the process between 9.0 & 10 might help:
https://community.dataminer.services/troubleshooting-sldatagateway/?hilite=cpu+average+load