Hi all!
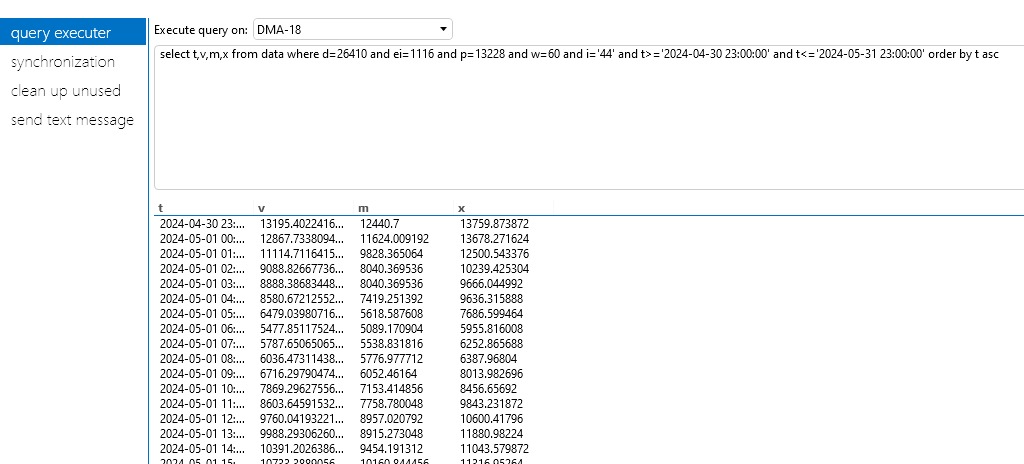
In a DMS with local Cassandra, a user used to run some queries from System Center like following:
After the migration to Cassandra Cluster (twice), there is one cluster with old data, not connected to Dataminer anymore and they are looking to recover some information using DevCenter.
When having local Cassandra and executing from DevCenter, keyspace was SLDMADB and the query was over data table:
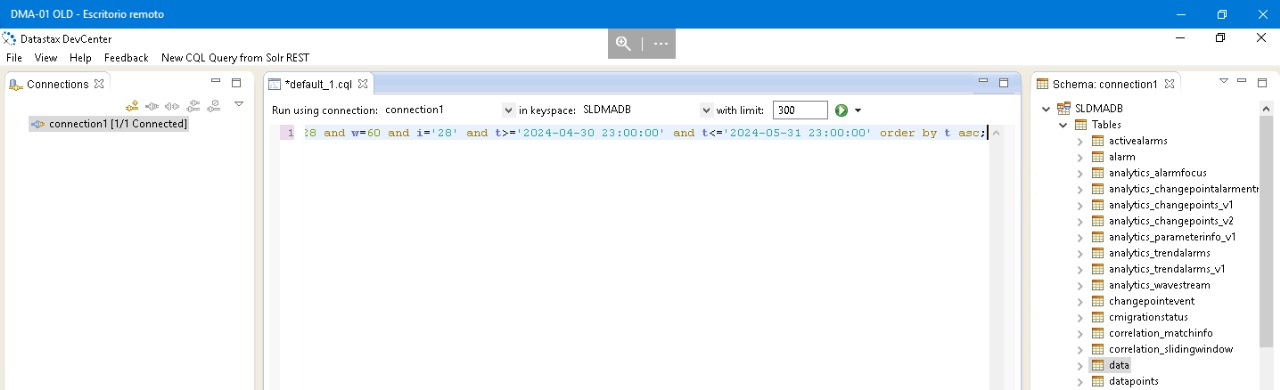
Now, if we would like to query the old Cassandra cluster, which would be the keyspace similar to SLDMADB in schema like following?
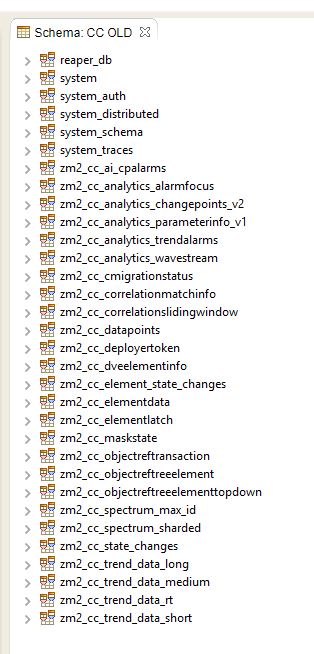
In the old data structure, all trend data (RT, short, medium and long) were in one table. This was the data table. As RT can generate much more load/size on disk than others, you typically want this to have a much lower TTL compared to others. With all the different TTLs on data in one table, it was almost impossible to compact out the data with Cassandra efficiently. For this reason, the data table has been split based on the TTL (rt, short, medium, long).
From the original command, you are using w=60 => hourly records, this would result in the medium trending. You will need to retrieve the data from the [prefix]_trend_data_medium keyspace (which holds only one table).
Thanks Michiel, the queries are intended to be done in a Cassandra cluster that was decommissioned as it was over an unsupported Linux version and it’s no longer connected to the DMS, but it is holding a lot of trending data that the user wants to retrieve.
Thank you Edson and Michiel,
I appreciate your comments regarding this topic.
I’d like to mention that, starting with the following base:
select * from zm2_cc_trend_data_medium.trend_data_medium
The syntax of the previous query was restructured to be compatible with the current structure on our CC, obtaining consistent results like this example:
select t,cv,cvl,cvh from zm2_cc_trend_data_medium.trend_data_medium where d=26418 and e=1291 and p=13228 and t>=’2024-04-30 23:00:00′ and t<='2024-05-31 23:00:00' ALLOW FILTERING;
t,cv,cvl,cvh,
2024-05-23 23:00:00,4533.41404047111,4229.480752,4995.519152,
2024-05-24 00:00:00,4199.52532088,3898.3644,4496.846656,
2024-05-24 01:00:00,3557.73504328667,2951.748216,4144.76016,
2024-05-24 02:00:00,3304.68334798667,2903.526632,3719.418992,
2024-05-24 03:00:00,3341.20302634,2618.713368,4060.133904,
2024-05-24 04:00:00,2326.80122630444,1871.857568,2766.162456,
2024-05-24 05:00:00,1987.99808151556,1694.46596,2480.91928,
2024-05-24 06:00:00,2167.37017932,1693.616096,2626.697976,
2024-05-24 07:00:00,2339.71141571556,2037.432944,3304.422168,
2024-05-24 08:00:00,2712.41159888889,2128.459328,3869.928272,
2024-05-24 09:00:00,3344.00844494444,2893.10492,3869.928272,
2024-05-24 10:00:00,2927.11627609111,2404.38756,3496.135048,
2024-05-24 11:00:00,2802.24351449333,2483.579312,3104.251064,
2024-05-24 12:00:00,3406.68724741778,2842.99852,4250.431016,
Unfortunately, it is no longer possible to extract the information from the OLD CC due to interruptions and incomplete information.
Despite the foregoing, I believe we have made progress in obtaining more information about the CC clusters through query execution, which we have been doing with an export of the trend via UI, which has become an ongoing task when there are more than 25 queries per CC.
Regards
Hi Michiel,
Additional question on index management within a query, as shown in the following example:
select t,cv,cvl,cvh from zm2_cc_trend_data_medium.trend_data_medium where d=26418 and e=1291 and p=13228 and i=’29’ and t>=’2024-04-30 23:00:00′ and t<=’2024-05-31 23:00:00′ LIMIT 1000 ALLOW FILTERING;
I obtained the following result:
Error,
CassandraConnection ExecuteQuery – exception while executing query: select t,cv,cvl,cvh from zm2_cc_trend_data_medium.trend_data_medium where d=26418 and e=1291 and p=13228 and i=’29’ and t>=’2024-04-30 23:00:00′ and t<=’2024-05-31 23:00:00′ LIMIT 1000 ALLOW FILTERING; – Object reference not set to an instance of an object.,
This index can be found within the element’s table.
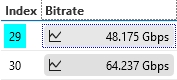
However, validating it with the query executor only shows a limited number of indexs within the table (less than what I’m looking for).
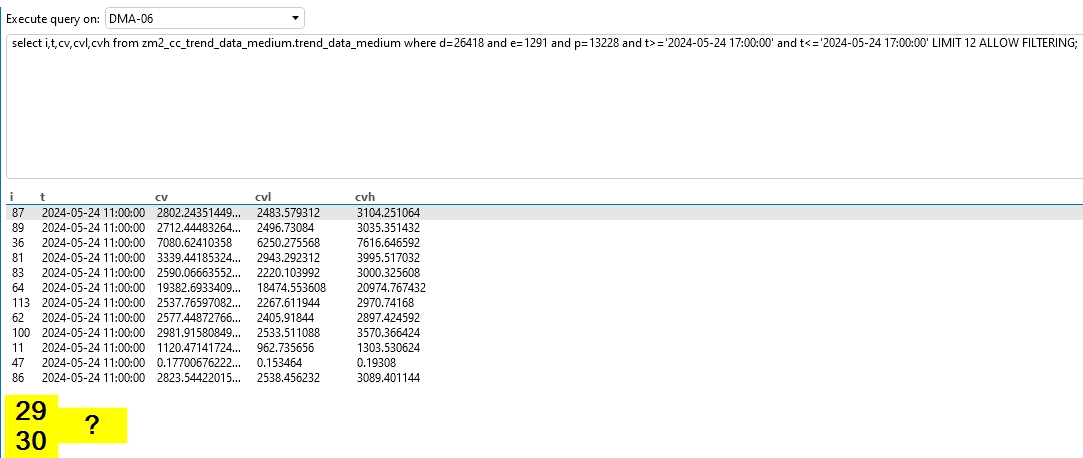
*Note: After 12 retrieves a error
Is it possible that I’m searching incorrectly or that this behavior is expected?
Pending, regards.
I noticed that you have a limit of 12 on your query. This means only 12 results will be returned. You can increase this, but keep in mind that you might cause a big impact if you set it too high and a lot of rows have to be returned. Note that you can automate the retrieval of trend data through an automation script that requests it to DM instead of through the DB which might be much safer.
Note: Probably you posted this follow-up as an answer to your question to add pictures, but note that I don’t get notifications on new comments on this answer.
Hi Michiel, in effect, this was the reason for adding images.
The intensity of the exercise is to test the ability to read each index in the element, as starting at 12 results in an error message: Object reference not set to an instance of an object.,
I need to get all of the available readings for indexs 29 and 30, which can be obtained via app and graphed to show the trend, but this is not the way I want to do it before deciding whether to migrate to a cluster or not.
Regards
Note: It is not advised to query the DataMiner DB directly. Mainly because this is not intended to be used as an API and could change over different DM versions. Offload DBs or using the export to CSV option on your trend graphs would be a better option.