Welcome to this roadmap blog item in which I’ll talk about data storage and the relationship with the hardware requirements in DataMiner and their upcoming evolutions. Databases are for some of you probably not the most appealing topic, but they are clearly an important part of our DataMiner ecosystem.
In the last 20 years, the database landscape has evolved massively with the introduction of NoSQL databases, document stores, graph databases, etc. In the same 20 years, the storage layer of DataMiner also went through a few evolutions, and more are coming up to make sure that you can benefit from the best technology has to offer.
Although DataMiner is in fact an in-memory database of your complete operational ecosystem in the first place that hosts its current status, we do need the persistent storage in order to be able to look back at what happened and it also allows us to leverage this information if we want to do historical data analysis and reporting. In the persistent storage we initially had two key types of data, being the time series (trend performance data) and the fault event data (alarms). These two have been further complemented over time to also support the orchestration layer, new types of data sources such as streaming data and unstructured data entering the ecosystem, the OSS/BSS functionality added to DataMiner and the element swarming coming up, and no doubt that there is plenty more to come.
The battle for resources
We have always deployed DataMiner and the database on the same computer resource, which allows DataMiner to act as a DBA. It is essentially a carefree turn-key solution. DataMiner makes sure amongst other things, that the installation happens, that backups are taken, that optimization and clean-up get done. Doing this today can be valid in specific circumstances, but we see that more and more of our customers have the requirement to store a massive amount of data which results in a battle for resources on the DataMiner servers. Both the storage layer and DataMiner really need access to the CPU, memory and disk. Separation of resource is the way forward. Doing so does makes it hard for DataMiner to do all the known maintenance actions but will allow us to (1) give the necessary resources to both storage and processing, (2) allow for tunable hardware requirements and (3) gives us new options on software level.
In DataMiner X, there are 3 main components:
- The DataMiner processing node
- Cassandra database for all our time-series data
- ElasticSearch indexing for most of the other storage
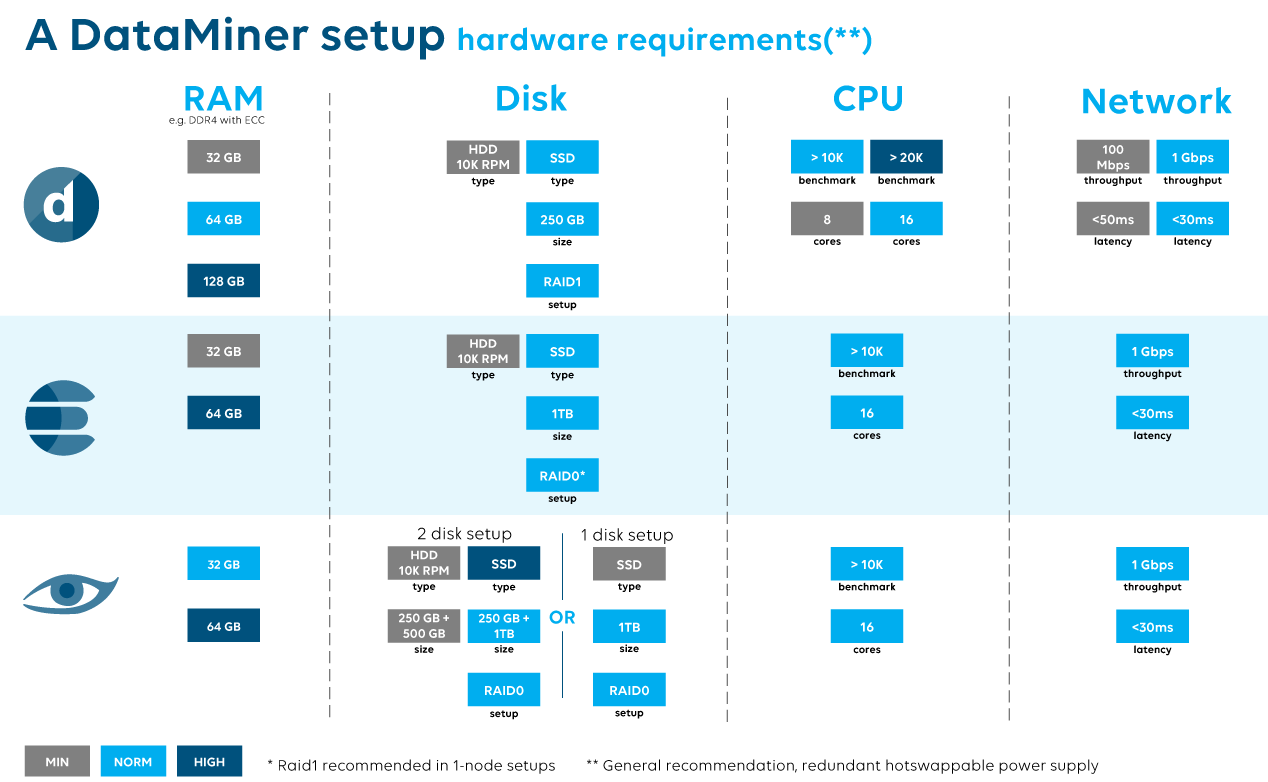
Let’s look at the specific hardware requirements of the 3 blocks.
DataMiner: DataMiner is there to make sure your entire ecosystem gets integrated, that you have fluid access to your data and that actions you want to perform are done instantly. As mentioned, DataMiner has an in-memory image of your current network status and has open connections to all systems integrated. So, during the process of setting and getting values, logging possible errors in communication and providing the user visibility to their entire network we have 4 important hardware components and the OS that can have influence.
- CPU: Is DataMiner CPU intensive? Sure, but mainly, it is very demanding in concurrency. A lot of actions in DataMiner happen in parallel. Is the typical action performed lengthy and bulky? Not really, only if you move to EPM/CPE environments where plenty of aggregation is needed, we see those heavy actions. As a rule of thumb, a CPU Passmark >10K is OK, >20K is needed in EPM/CPE environments.
- RAM: As your system is loaded into memory, a DataMiner system needs quite a bit of it, but it depends clearly on the size of your network. Again, we see a bit of a difference between ‘regular’ DataMiner systems and systems where a lot of aggregation is needed. On systems where there is not too much aggregation, we see that the memory consumption is quite stable. If you have aggregations, you’ll notice there is peak demand during these moments. There is no real magical number that we can state as a range; from 32GB to 128GB might be valid (although 128GB is exceptional). A detail, but also the data-rate and latency are important in your choice of RAM. (e.g. DDR4-3200 with ECC).
- Network: The network speed and latency to your DataMiner are an important part too of a great system. Pure inter-DataMiner communication is not so much about the big volumes but more about smaller messages, so a small latency is important. For read and write actions to the storage nodes, a nice throughput is recommended. The common giga-bit networks won’t be overloaded by a DataMiner. We understand that keeping the latency low is not always possible towards remote sites. As such, having a higher latency, is not problematic for synchronization of your cluster, but it could become more of a topic if a high number of values needs to transfer between remote nodes. You can check with your contact person if this would be the case.
- Disk: DataMiner as such (so forget the persistent storage for a moment) doesn’t need disks with huge capacity. A backup might take some space, but you can argue these shouldn’t be stored on the local disk or server. Having an SSD, on the other hand, would be useful as we regularly write to files, and the OS will only benefit from this. Basically, a 250GB SSD will do the trick. If you make it a hot-swappable RAID1 pair, you’re all set.
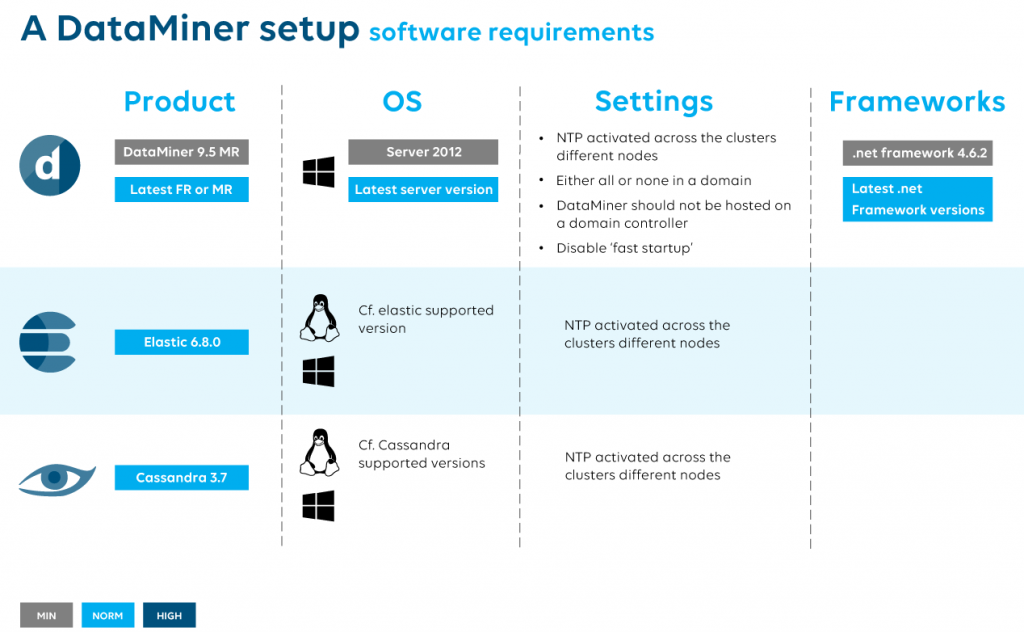
- OS: We always follow the latest available server version, so if you install today, we highly recommend using the latest Windows Server OS version. This not only allows you to make use of the latest features, it also provides the longest support and security patches. At the time of writing, Windows Server 2019 is the one to install.
- Time: If you have more than one DataMiner node in your cluster, it is a requirement that the time is synchronized in the cluster (NTP).
Cassandra: Let’s do the same exercise for Cassandra. Clearly, we follow here what Cassandra has as official guidelines. Do note that Cassandra prefers to scale out instead of scaling up. But maybe first, why do we have Cassandra in DataMiner? Cassandra is used in DataMiner to store all the trend data and the non-volatile values of parameters. The more data you trend, the higher the load will be on your Cassandra node.
- CPU: Like DataMiner, Cassandra is highly concurrent, and requires quite some CPU power for actions like compaction or repair, but also the write-speed is bound to the CPUs performance. DataStax recommends 16 logical cores for production environments.
- RAM: While the size of RAM depends on the amount of hot data., there are a few conventions to follow:
- ECC RAM should always be used, as Cassandra has few internal safeguards to protect bit level corruption
- The Cassandra heap requires 8GB of memory, on heavily loaded systems it might be required to even increase this.
- To summarize: 32GB is enough, where we assign max 8GB to the JVM.
- Disk: Ideally your Cassandra server has 2 disks. This is mandatory if you use HDD, if you opt to use SSD, this requirement is less pressing. The reason is that Cassandra has 2 write cycles, one for the commitlog (will be accessed for every write from the client application), and one for the sstables (the real storage of the data). Clearly your read and write speed will benefit from an SSD. There is no need to opt for RAID1 as replication should be handled by the cluster configuration.
- Network: A high-speed network is required to be able to transfer the data between the different nodes. Clearly the higher the replication factor the more data that needs to be transferred in the Cassandra cluster. There is no real specification around the minimum network latency required to keep your Cassandra cluster going. Having it as low as possible should be the goal.
- OS: Cassandra can be installed on the OS of choice, preferably a 64-bit one.
- Time: If you have more than one Cassandra node, it is a requirement that the time is synchronized in the cluster (NTP).
Elastic: Elastic is the second database we need on a DataMiner. Why 2 databases? Well, we have stored alarm events in Cassandra, but due to the nature of queries that are done on alarm events, Cassandra is not the best fit. By using Elastic, which is an indexing engine, we can provide way more options to the user querying queries, suggestions, reporting, etc. It does come with the extra requirements, so here’s another overview where we also follow the documentation from Elastic. Same as Cassandra, your initial Elastic cluster should not be over-scaled. Adding nodes when there is need is a better approach.
- CPU: Elastic is less demanding on CPU so a >10K CPU will do the trick. Having an extra logical core in favor of a few extra CPU cycles is preferred.
- RAM: A server with 64GB of memory is the ideal world. Having 32GB would still be OK, but don’t overdo it by adding 128 GB of memory, as heap sizing and swapping becomes a problem.
- Disk: SSD is the way forward, if you do opt for HDD then 15K rpm is advised. There is no need to opt for RAID1, replication should be handled by the cluster configuration.
- Network: Gigabit ethernet for throughput and low latency for easy cluster communication are a requirement. Elastic assumes that all nodes are equal, so latency between the different nodes in your cluster should be similar.
- OS: Depending on the supported OS’s by Elastic it can be installed on the OS of choice, preferably a 64-bit one.
Overview:
Below you can find the information as a quick overview. Color-coding: grey, as the minimum requirement, light blue as the default to be all set, the darker blocks are for high-end applications, but not always needed.
Wow, excellent information here. Thanks.
Thanks for the great insights!
Very useful, bookmarked as one of my references.
Great overview! Will come in handy for future integrations.
Great overview, everything we need to know and to pass along to our customers is very well summarized in this post. Thanks!
Excellent overview!! It could be great to have some words on how these requirements can be mapped to virtual environments.
Great article, thanks