What are some recommendations / best practices for long term data storage while still maintaining access to the data in Cube? Currently we have elements that generate large volumes of data each day. To keep the element performant, we're archiving data to CSV stored in the Documents folder. This works nicely in keeping the element from getting overloaded, but makes the archived data very difficult to analyze as it is all "chunked" up. It seems to me there has to be a better way!
The end goal is to be able to continue to offload data to keep the element performing nicely, but at the same time improve the visibility into historical data. Here are some of the things we're hoping to achieve:
- Elements can "archive" historical data as needed to a DBMS. This could be the standard Cassandra Node (using a different DB than the standard DM DB), Elasticsearch or some other DBMS.
- The historical data should be searchable / accessible from Cube for reference. Not sure exactly how this would work, but it seems to me it would need to be done in a way that bypasses the standard DM Data Layer.
- Historical Data should not be trended or evaluated for alarming.
Perhaps the Central Database feature could be used for this? If so, what I'm unsure of is how we'd get the information back into Cube for searchability.
I know this is probably not a simple topic to address, but one that's been on our minds for a while. Wanted to see what people's thoughts are. Thanks in advance!
Hi Michiel,
The immediate use would be storing the test results for VOD testing. We’re generating something like 4000-5000 tests / day which is too much data to store long term in DM. That said, it would be nice to be able to see a full history of testing for a given asset without having to parse though the CSVs. In this case I could see that we’d want to retrieve from the archives a list of test results for a given Asset GUID. Hope this helps!
Hi Jamie,
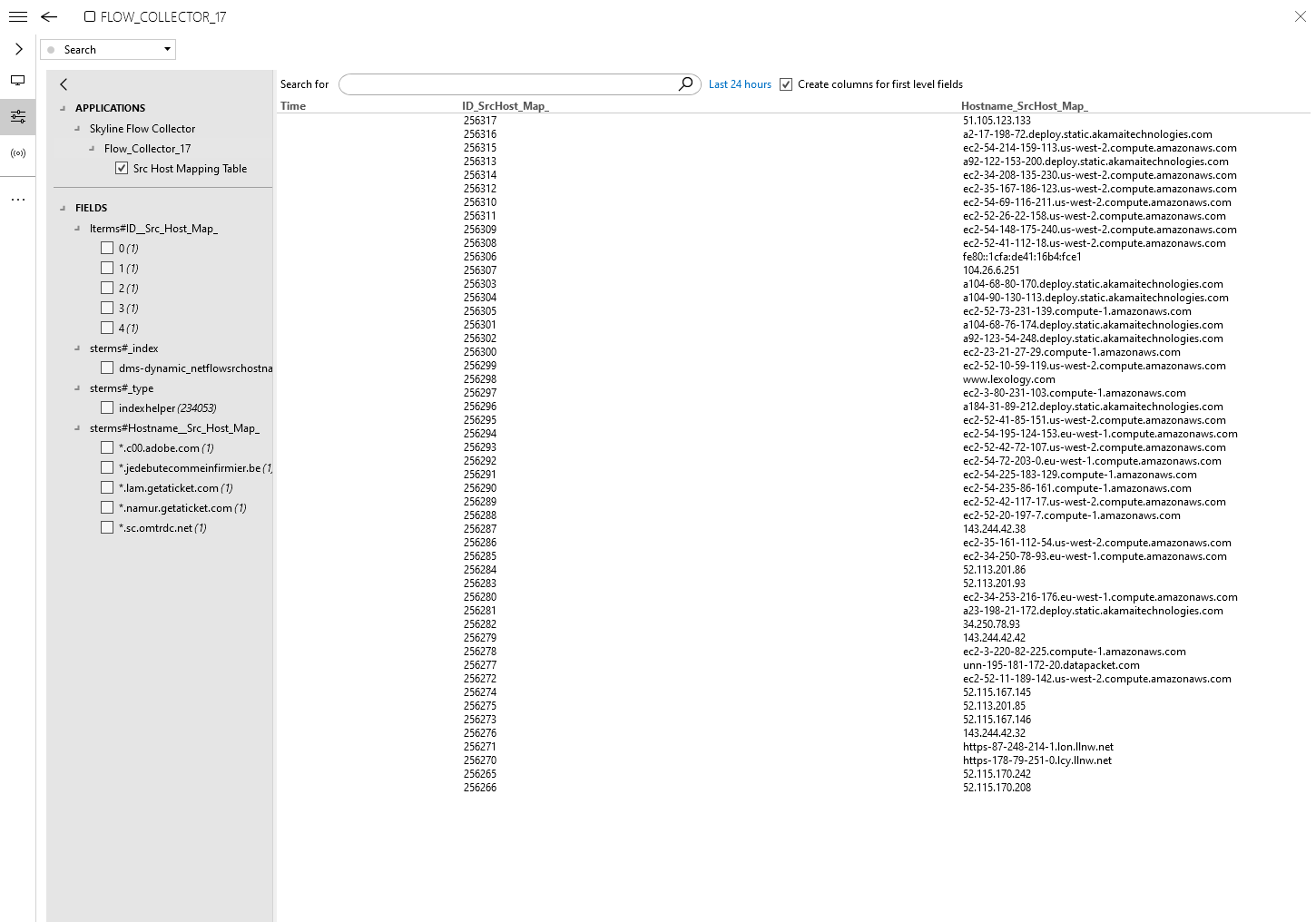
A similar case has been done before, utilizing the LoggerTable functionality and Elastic-database. The protocol would collect the data and push it straight to the Loggertable when available using a DirectConnection.
The data would then be available:
- Via a query UI in the element card (which supports ad hoc querie and searches
- Dashboards (as datasource for the dashboards)
Alarming and trending would not be possible on the loggerTable. If this is needed then the protocol can still do on the fly calculations on the incoming data, these can then be pushed as a regular metric in dataminer, which can be monitored/trended.
The Generic sFlow manager is a good example of this functionality. Which handles a large number of netflow packets for long term storage and querying.
Central database would not be suitable for this, the intended purpose for this database is to offload data for external usage. The data cannot be accessed from within DataMiner.
Thanks Brent! We’ll give that a look and see if we can make it work. Sounds very promising!
To make the search possibilities more user friendly, you could add a dashboard using this data to a visio page to make it accessible directly in Cube.
Hi Jamie,
Just to make the requirement more clear: what kind of data are we talking about? Is it the trend data of an element you want to store with high detail for a long time, or do you need log type data where you store a timestamp with a number of values, or maybe something else?