We are currently experiencing an issue with Dataminer causing all our collectors to not be available. When looking into the errors, we see the following : No connection with the Cassandra database at localhost.

Does anyone ever had this issue ? How can we fix this connection problem ?
Hey Samuel,
Losing connection with the database can indeed cause collectors to not start up properly as DataMiner will fail to read the necessary data from the database.
Losing connection with the cassandra database can happen for various reasons. A good start will be to check if the cassandra service is actually running. If not you might want to start this service and see if this resolves the issue.
If the service does not want to start then there is an issue with the cassandra service itself, which usually means someone changed something to the config (The cassandra.yaml or the registry properties). Reverting these changes should fix this. Otherwise the issue will be logged in either the cassandra logging (C:\program files\cassandra\logs) or the apache logging (C:\Windows\System32\LogFiles\Apache).
If the service is running. Check if it is reported as UP by executing “C:\Program files\cassandra\bin\Nodetool status” in a command prompt. If it is up you can verify the connection using devcenter (located at: c:\program files\cassandra\devcenter ). If either of these report the cassandra as down, then the issue likely is in cassandra and a reboot of the service might help.
However if you can connect using devcenter, then the issue likely is in Dataminer. You can check the SLDBConnection.txt logfile to see what fails during the communication with cassandra (unresponsive nodes, Incorrect password, Timeouts,…). This should indicate if there is a configuration issue preventing a connection which needs fixing. If nothing indicates issue here then a dma restart is likely to fix the issue.
I experienced the same problem. Here is the reason why I was facing the issue and how I fixed it.
I was doing the migration of the cassandra failover pair (online agent + offline agent) to new HW. The old system was at version 9.6. In the migration process I took the backup of the DMA-main-old (and aimed to remove the DMS.xml from there which has to be done according the documentation, but the file was not already present there) and restored it to the DMA-main-new. All right at this point.
The problem appeared when I then upgraded the DMA-main-new to the 10.1. I was obtaining exactly same alarm as described by you.
After some investigation I found the Cassandra at the DMA-main-new was handling two nodes – 127.0.0.1 and 10.180.11.220 while it had to handle the 127.0.0.1 only. The latter one was the IP address of the DMA-bu-old – the offline agent of the old system. I don’t see any other way how it got there but the configuration restoration from the old system.
So I used the nodetool to fix that. The “ghost” node was shown as down so I was allowed to remove it. Here the CLI output
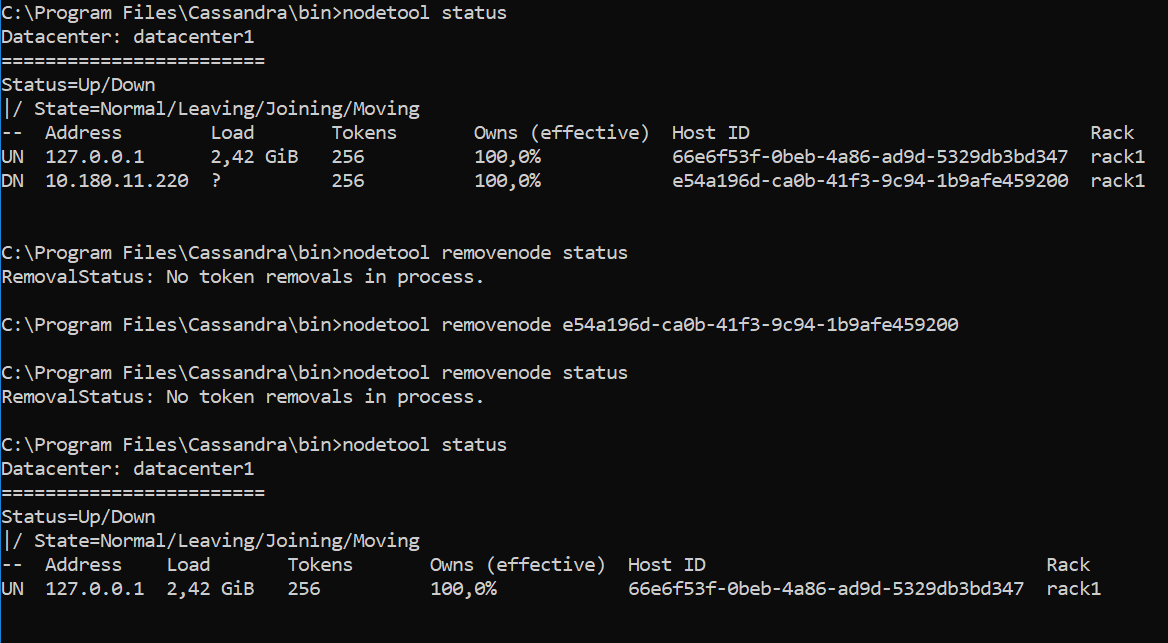
After that I rebooted the server and problem was gone.