In the first of a series of posts, we want to share our experiences around CI/CD. The end goal is to enable our customers to create this kind of environment and to show them how to do that with DataMiner. So there’s more to come!
It seems like a long time ago now, when the topic of continuous integration, delivery and deployment was raised at our annual ‘Focus Days’ with the Skyline Director Team and C-level Management. Just one of a plethora of topics brought up to work on, but for those involved, it became something quite consuming. The journey we embarked on with this program made us question everything we do, how we do it, and why…. and so it should.
It’s tempting to make your CI/CD program simply an automation of your current processes. While already a useful thing, this misses an opportunity. The opportunity to examine your business model and how to currently support that with procedures and practices. We fall into habits because ‘that’s the way it’s always been done’ and sometimes the way we do things is just fine, but it’s often not. Before thinking about technologies such as Jenkins, Team City, GIT, etc., to support us, we need to look at what we’re supporting.
Firstly, you need to examine the basics of what you do and try to write down the ideal way of doing it. That’s easier said than done, but overcoming the challenge brings rewards. It’s important to realize that if your process doesn’t work on paper, it won’t work when automated either.
The main business of Skyline, put simply, is to develop and deliver our core DataMiner software as well as completely out-of-the-box solutions (what we call our DataMiner Apps) and fully tailored solutions to customers and partners in the media and broadband sector, enabling them to orchestrate and monitor their entire infrastructure, straight across any vendor boundaries and technology domains. But DataMiner is essentially a full-featured framework that can talk to and control anything that is network aware. Our open source protocol drivers and built-in automation capabilities enable any kind of system to be built, and that’s why people love DataMiner.
However, because of this flexibility we also have complexity, both in the underlying code behind things and the configurations possible. Delivering things the old way was becoming more and more inefficient and difficult to do whilst guaranteeing quality, especially when iterating new versions.
Enter CI/CD…But where do we start?
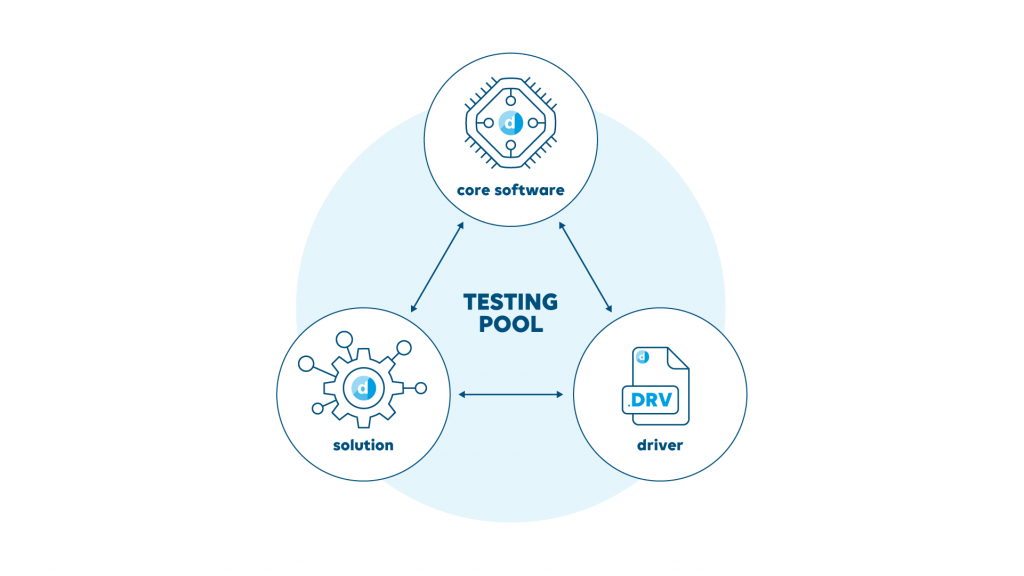
Standardize your testing infrastructure
One of the main challenges is to ensure that your quality infrastructure is manageable and supple enough not to hold you back. It’s no good having a cast iron set of quality gates if that system is tied to a specific infrastructure or hardware, especially when multiple squads are working on core code and solutions based on it. We need to be able to deploy automated testing code anywhere, without much adaption, if any at all, or we start to generate new bottlenecks. So first we had to finalize our standards and practices around this. Fortunately, we were well down the road already on this topic. Put simply, we needed a common API and reporting hub for testing and importantly, we needed buy in from all teams to use and contribute to it. People are always happier working to a standard when they have a stake in it.
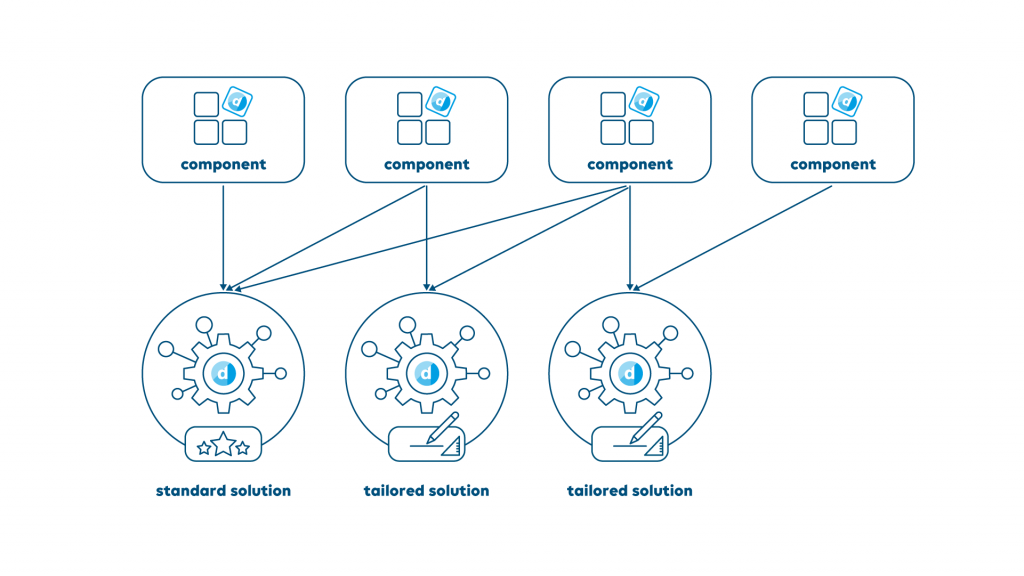
Explode the BOM
In a complex inter-reliant development scenario, it’s possible to quickly have discreet software components that are used in multiple implementations and for multiple purposes. In our case, the situation might arise where a specific protocol driver that enables communication with a certain third-party product is used in various scenarios, with sometimes different specific technical and business logic requirements.
It is tempting to make a new version of the component, specific to your requirements and maintain it yourself. The problem is that you increase the overhead in maintaining these components and won’t benefit from improvements to building and testing processes that are constantly being updated in the main driver component pipeline. Also, improvements to the component itself are not shared. On top of that, it’s also administratively inefficient.
For a very long time, the manufacturing sector has used the concept of a ‘Bill of Materials’ or BOM, which described all components that make a certain item. Any changes to any component are approved by all parties using and developing the components. We can do the same with software components, leveraging a tool like Jenkins to automate the approval and validation process, to ensure that the component is compatible with all its applications and use cases.
Our customers are also our collaborators
Another major shift in our thinking happened when we started to draw out our processes on paper. Our customers and partners are a valuable source of knowledge and experience in the use of our software in their domains. Many are experts in their fields and produce some of the most exciting projects. Instead of simply delivering software to them as an end goal, we should be collaborating with them more. Let’s plum them into our pipeline!
It’s important when doing this that we understand that some customers may want to work directly with our pipeline, they might also want to develop their own stages. Everything can still be run through our pipeline to ensure our standards are also applied, but it means that they are involved in the process at all levels. We increase visibility on the customer’s needs inside our business and involve them from the early stages. This way we can avoid misaligned requirements, creep and develop a sense of collaboration, which is very beneficial for all.
Our desire is to empower our customers to build agile operations for themselves, leveraging the power of DataMiner. Having their own DevOps teams creating powerful and continuously evolving DataMiner solutions, leveraging our CI/CD infrastructure to accelerate that.

The next step: prevent configuration drift
Another enemy of a successful CI/CD implementation is configuration drift, and this is the next major step in our journey. How many times have you heard “It worked on our test system, but not on yours?”. Coming back to the previously mentioned concept of a standard testing infrastructure, where all testing can be deployed anywhere, we also need configurations that cannot be changed without going through CI/CD. This makes sense when collaborating with the customer. They have direct access to change configurations, but only through the same pipeline we use. The changes are then also immediately applied to our development and test labs and automatically tested against the latest core software versions and drivers.
Also, its advantageous if production setups can be directly ingested into testing platforms. Some say this is the most important thing to get right and we’re about to find out how we tackle this challenge. There are many difficulties in this.
One thing’s for sure: it will be an interesting and exciting new part of the journey.
Interesting article Simon!
Great, Nice article.
Nice overview.