In recent years, broadcasters and providers of media contribution and distribution networks have been migrating or are at least planning to migrate to IP-based video networks. The benefits that this new technology brings are diverse.
All-IP media transport networks allow to leverage virtualization in an agile manner and transparently combine multiple media formats over a single converged network. Whether one needs to switch multiple audio sources, as well as compressed and uncompressed video in HD, UHD (Ultra High Definition), HFR (High Frame Rate) or HDR (High Dynamic Range), has no impact on network architecture and solutions.
Another change that all-IP media transport brings is the way we think about redundancy or fault tolerance of a system. For broadcasters and service providers, high availability has always been a key concern in designing system architectures.
Redundancy in a classic baseband scenario is achieved by simply sending every signal twice, thus doubling all infrastructure and costs. This means that we somehow have two versions of the same signal and transport each one separately over a separate dedicated network segment, ending up with two signals on the other side. If one connection or device fails, one of the two signals will still reach the other side.
If you would compare this with a faucet in your bathtub at home, you would have a system with two faucets, with water sometimes coming out of either of them. What you really want, however, is one faucet which always has water coming out of it whenever you open it.
In an IP transport network, however, there are more different ways of organizing redundancy:
- Transport Redundancy
- 2022-7 or “Dual Illumination”
- Dynamic path orchestration
- Quad redundancy
- Source Redundancy
- Destination Redundancy
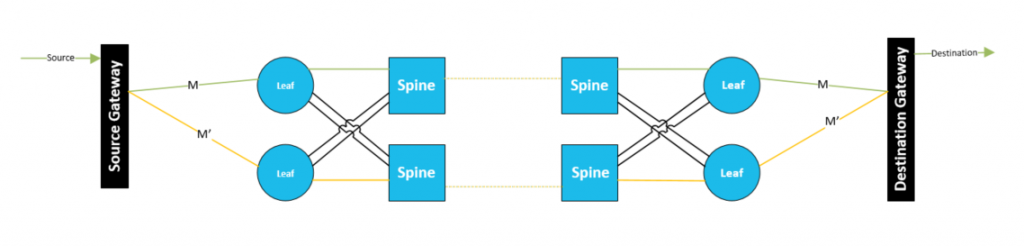
Dual Illumination
This is what we can accomplish with the SMPTE-ST2022-7 standard. In this scenario, the source gateway sends an identical, yet duplicated multicast media streams in red and blue networks using the Real-time Transport Protocol (RTP):
Dynamic Path Orchestration
With the help of a multi-vendor orchestrator like DataMiner, an alternative for this kind of redundancy can be achieved (without using SMPTE ST 2022-7) by automatically setting up a new path for a multicast stream upon failure of one of the network links or components:
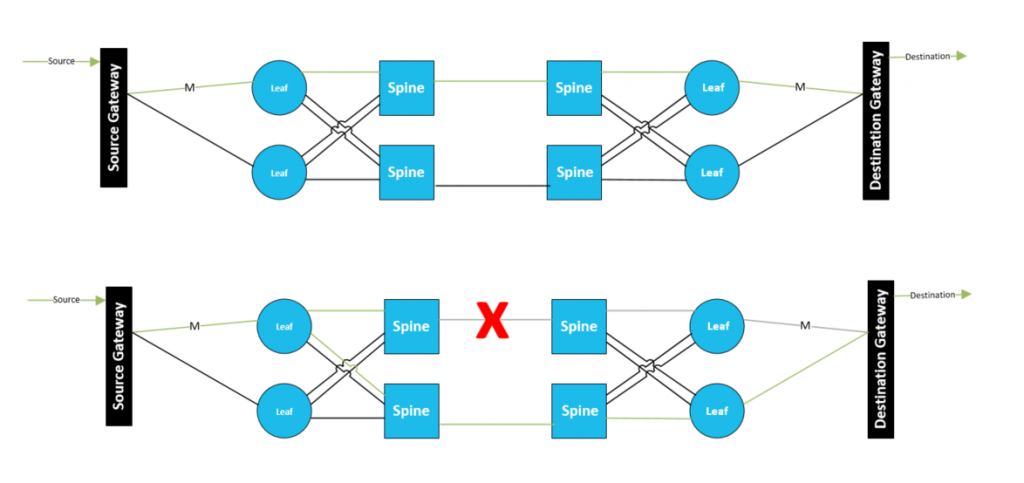
The main advantage of this redundancy architecture, is that in a normal situation, no duplicate bandwidth is required for every signal. It is sufficient to reserve a bulk “emergency” bandwidth in each part of the network for the emergency rerouting of the most important signal streams. In this scenario, the switchover times are higher, and service may be impacted for a short period of time. The benefit is, of course, that the service consumes bandwidth only once in the network.
Quad Redundancy
In an extreme case, one might even consider using quadruple redundancy. Here, we have dual baseband input signals, which are both transported over the network with 2022-7 protection. In total, there will be four versions of the same media stream travelling through the networks:
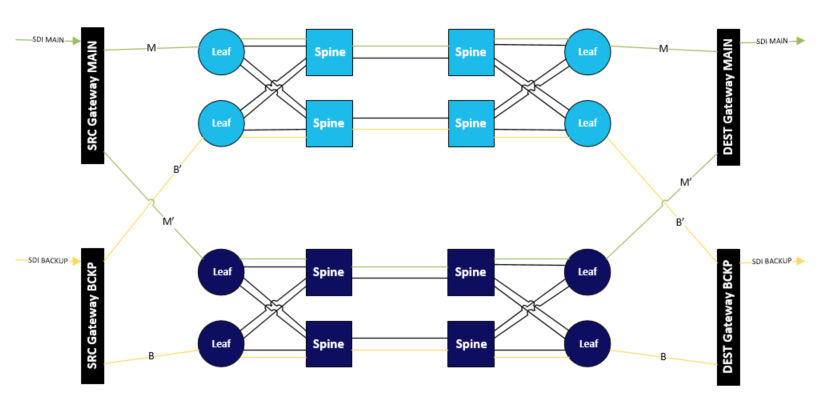
This is the most expensive architecture in terms of bandwidth and the duplication of hardware resources. A reason to choose this kind of setup could be technology redundancy, i.e. the red and blue networks are built using two different technologies. This setup keeps services running when single failure conditions occur, but also when multiple simultaneous failures happen in the network. Adding to that, resiliency is still available even during network software upgrades or other maintenance activities.
Source Redundancy
In case a failure of the source stages is of concern, source redundancy can be deployed:
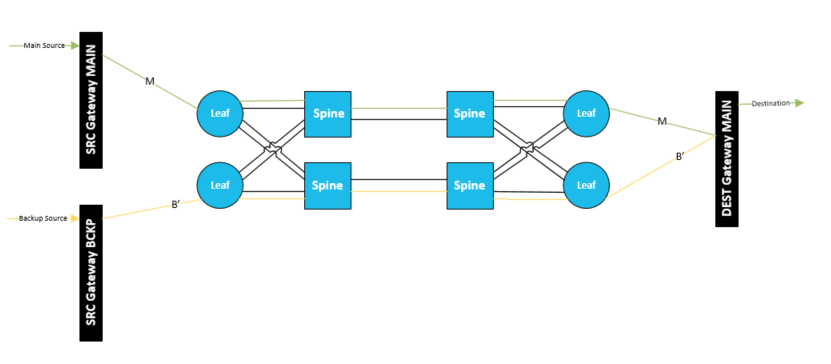
Here, there are two different sources, which present themselves as being two 2022-7 streams of the same signal, and the receiver will handle the two streams as such. This is therefore also called “receiver only 2022-7”. Since the sources are not synchronized when ingested into the IP network, the switching at the destination gateway may or may not be seamless. This depends on whether frame sync is available in the destination gateway.
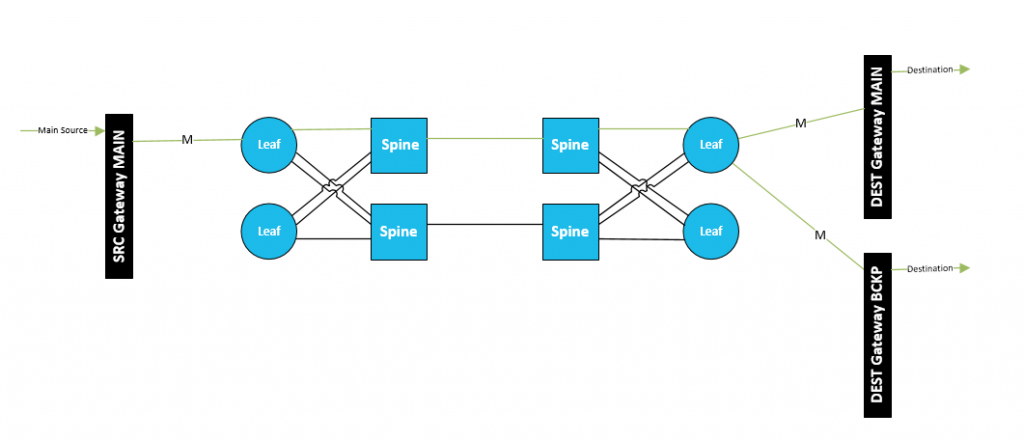
Destination Redundancy
In case of destination redundancy, the signal is simply routed to different destinations at the same time. There are different possibilities for the routing of these two signals. For optimizing the bandwidth usage on the network, the two destination devices can pull the signal from the last leaf. Remark that this redundancy of the destination gateways will often be combined with 2022-7 redundancy.
Conclusion
To summarize, here are again all redundancy architectures. This time with their associated values in terms of cost on one hand, and service availability on the other. The unit for cost is “what bandwidth multiplicator do we need to apply to our minimal bandwidth to provision a single service”:
| Dual Illum | DPO | Quad Red | Source red | Dest red | |
| Cost | x2 | x1 – x2 | x4 | x2 | x1 – x2 |
| Availability | 200% | 200% | 400% | 200% | 200% |
There is no good or bad with any of the chosen redundancy schemes. Every choice has its pros and cons, and therefore, every redundancy mechanism serves it purpose. But there is more to it:
- Efficient redundancy relies on smart decision making based on a system-wide view. An end-to-end multi-vendor orchestrator facilitates combinations of multiple redundancy mechanisms. Using 2022-7 redundancy on the data plane, using source gateway redundancy, etc. Combining multiple redundancy mechanisms without ending up in race conditions – typically resulting in endless toggling of signals – requires an intelligent orchestrator like DataMiner.
- Don’t limit yourself by the limitations of the control software you got from your equipment vendor. Choosing the optimal level of redundancy is to be made for every individual flow, this should not be a system-wide choice. A flexible, service-aware orchestrator allows you to select the level of redundancy (and cost) for each individual flow, or group of flows (e.g. premium sports content by default may run in quad redundancy, whereas new content may use dual illumination).
- Reserving bandwidth in the network and between facilities, and also ensuring the availability of edge gateways to handle the redundancy schemes is essential to a reliable operation. The DataMiner Resource Manager reserves the minimum required bandwidth for every flow, for each selected redundancy scheme.
- Last but not least: context matters. Signal flows come and go over time (scheduled, operator selected), they often change characteristics (described in SDP and transport files), depend on other signals (e.g. SMPTE ST 2110 relies on the system PTP time sync), some faults in the network require active measurement (synthetic testing), etc. Any intelligent redundancy switching needs to take all these data sources into account to make thoughtful decisions.
In conclusion, migration-to-IP media transport networks, creates a whole new world of opportunities regarding redundancy and availability. The value of a specific architecture, however, will depend greatly on using an intelligent, vendor-agnostic monitoring and orchestration system, and crafting a careful design of the whole setup. But when everything is done correctly, these kinds of architectures can leverage the full potential of all-IP media networks to deliver very high availability systems, not only on paper but also in practice.
Great Laurens!