Hi,
I encountered that the request-id of some protocols/elements goes into negative (I assume a integer overflow).
The related device answers with a "normal" positive request-id.
I assume, that the dataminer cannot match this response to the request it send, so the element goes into timeout.
In the past a restart of the element in the dataminer was a possible workaround to reset the ID.
Not sure if it is now not longer possible with the dataminer version (10.1.0.0-10049-CU1) we are using or if it is driver related.
So the question is, how can i prevent the usage of "unnormal" negative request-id's, to get rid of the root problem without a workaround? As I don't write protocols, is the request-id handling specified in the protocol or in the dataminer core software? Where do i need to look for this?
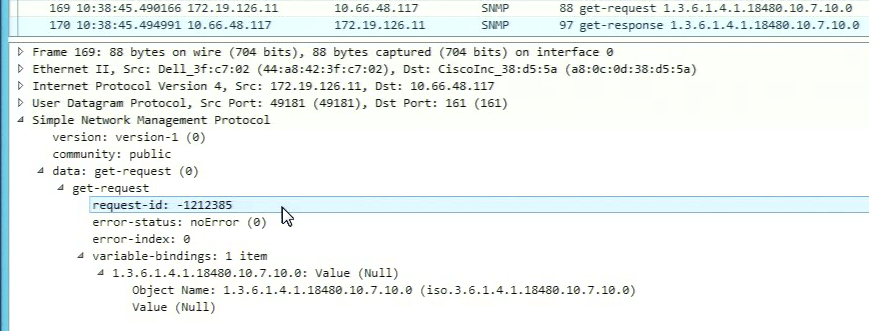
-> get-request
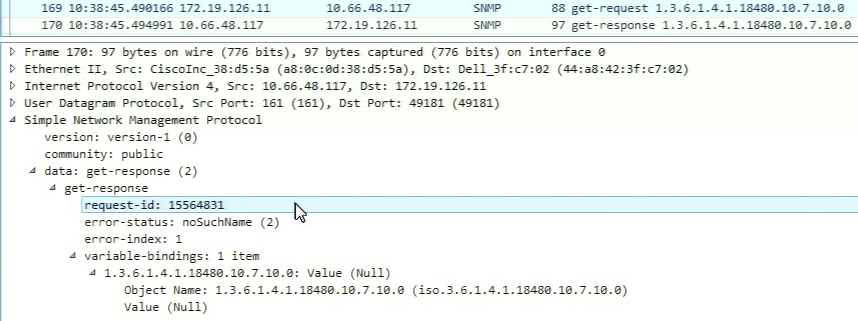
-> get-respond
Best Regards
Thomas
I'm not an expert on this, and it seems to be unrelated (as it seems to be the opposite if I understand correctly), but in the past we experienced some problems with equipment from certain vendors that had an SNMP stack with a bug that caused their ID to go negative (which is not in line with the SNMP standard). I don't recall all the details, but just wanted to mention it here to make sure that this is not related. I believe we encountered this starting a long time ago with Tandberg products (and they fixed that problem, but I believe then it resurfaced again in new firmware release). Just in case this could be relevant information.