Hi,
We are trying to get an redundancy group working on Ateme. We have added same channel on both Atemes and the service is started at “Prime” and stopped at “Backup” and we are trying to get the redundancy to stop the main and start the backup if there will be any alarms at main.
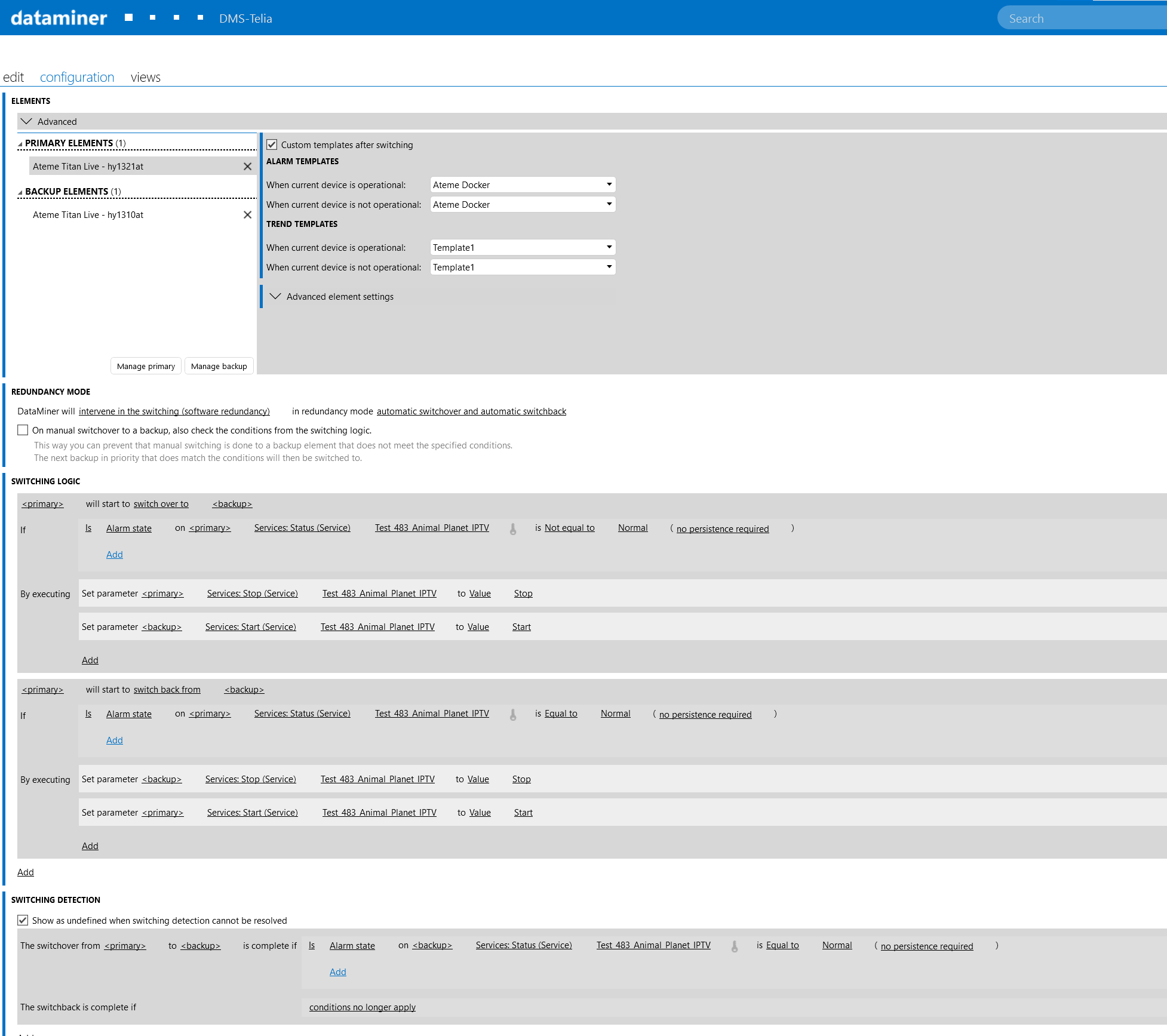
We have done like this picture, are we totally on wrong way or?
Does any one have any examples how we shall configure this?
// Thomaz
The main wonky part here appears to be the “switching detection” condition, which is the condition that defines which device DataMiner sees as the operational one. These conditions get applied at any time, regardless of any switching logic defined. In the configuration from the screenshot, DataMiner will see the backup device as the operational one as long as it doesn’t have any alarm event.
It’s probably also not the best idea to trigger on alarm state here: if both devices have alarm states, the redundancy group will end up in limbo.
If there’s any parameter through which you can know that a backup device is the operational one, my suggestion would be to put the switch detection on there. e.g. something like “when <service status> is <active>”
Also see Creating a redundancy group | DataMiner Docs . There’s a video also on redundancy group configuration.
Another great video is the one from the Administrator training, Bert explains everything and shows a practical example on what do and don’t
https://community.dataminer.services/courses/dataminer-administrator/lessons/redundancy-groups/
Thanks you all for the help. We have now got an “easy” redundancy test up and running who is switching on a “critical” alarm. Stop the service and start the service at another hardware.
But, is thee any way to solve if we are “loosing” the hardware, the hardware will die and get into “timeout-state” in Dataminer? We tried to stop the management port in the switch and DM lost the connection to it, but could not switch to the other hardware because the redundancy group failed.
Hi Thomaz,
I’m not sure I fully understand your question. Could you provide further info there?
In general, DataMiner elements will go into timeout state when they cannot communicate with the device they are supposed to monitor. That part feels expected.
If the primary element of a redundancy group is in timeout state, I would expect that within DataMiner, manual switching to the backup element should still work. Even automatic switching should work when configured to do so.
It would be interesting to learn what you are seeing at the DataMiner level and how exactly the redundancy group is failing?
As this question has been inactive for a long time, we will now close it. If you want further assistance, could you post a new question?