Dear DoJo masters,
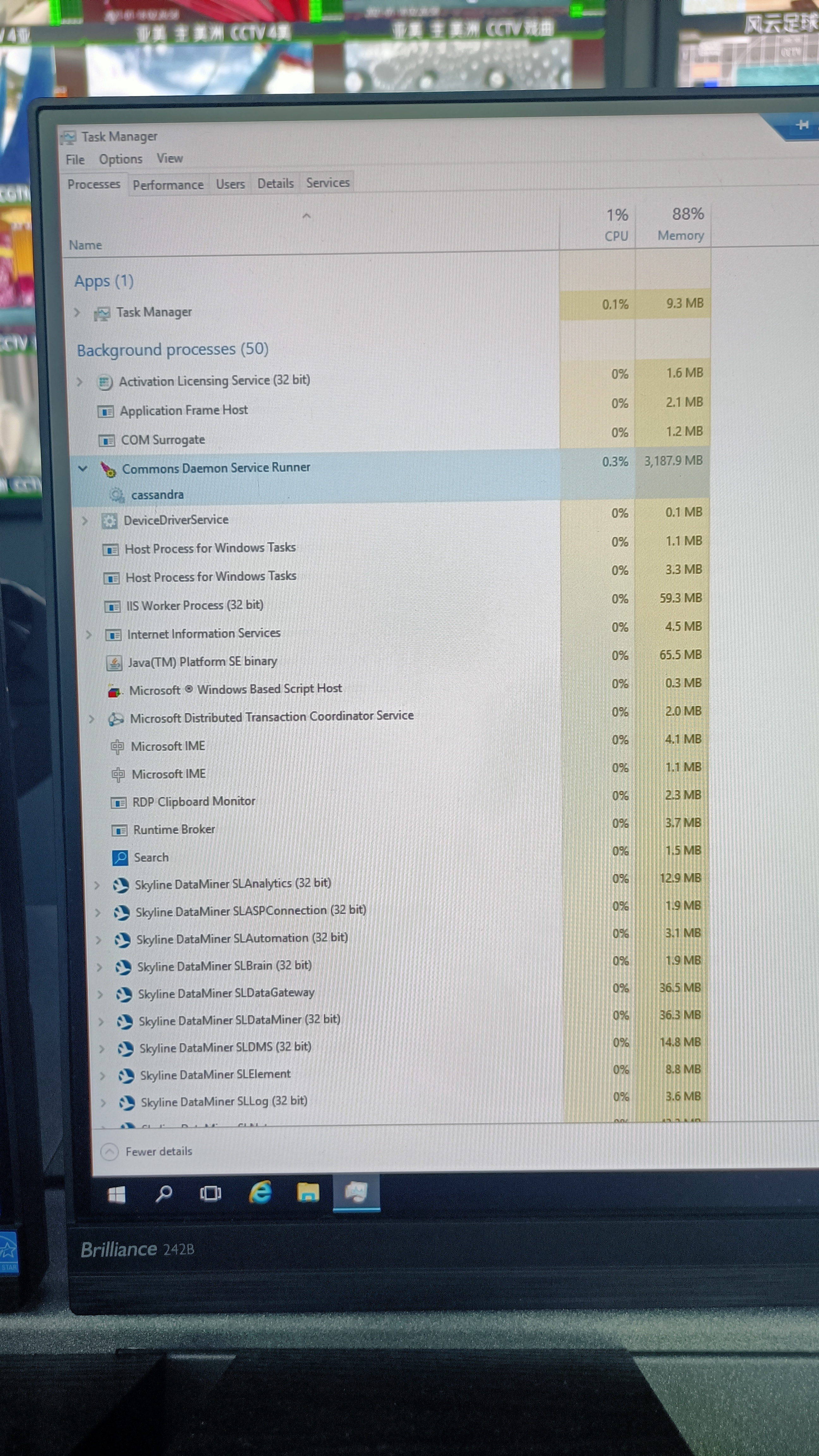
End-user have an Agent with 32 Gb ECC Ram.
Every time Cassandra service starts running, Prunsrv.exe process shown physical memory utilization in OS TASK Manager is DIFFERENT from the utilization show on resource monitoring (OS built-in) & also, DMAGENT ms-platform monitoring, and the value shown on OS task manager is far less than DMA agent show value, and it actually trigger alarm everytime. why this could happen?
and the memory utilization is surge at 90%-99% could happen.
Apparently, there are no other processes which occupying those bandwidth as reflected in task manager.....which means 10-15Gb Physical memory usage is not shown on task manager....any similar experience?
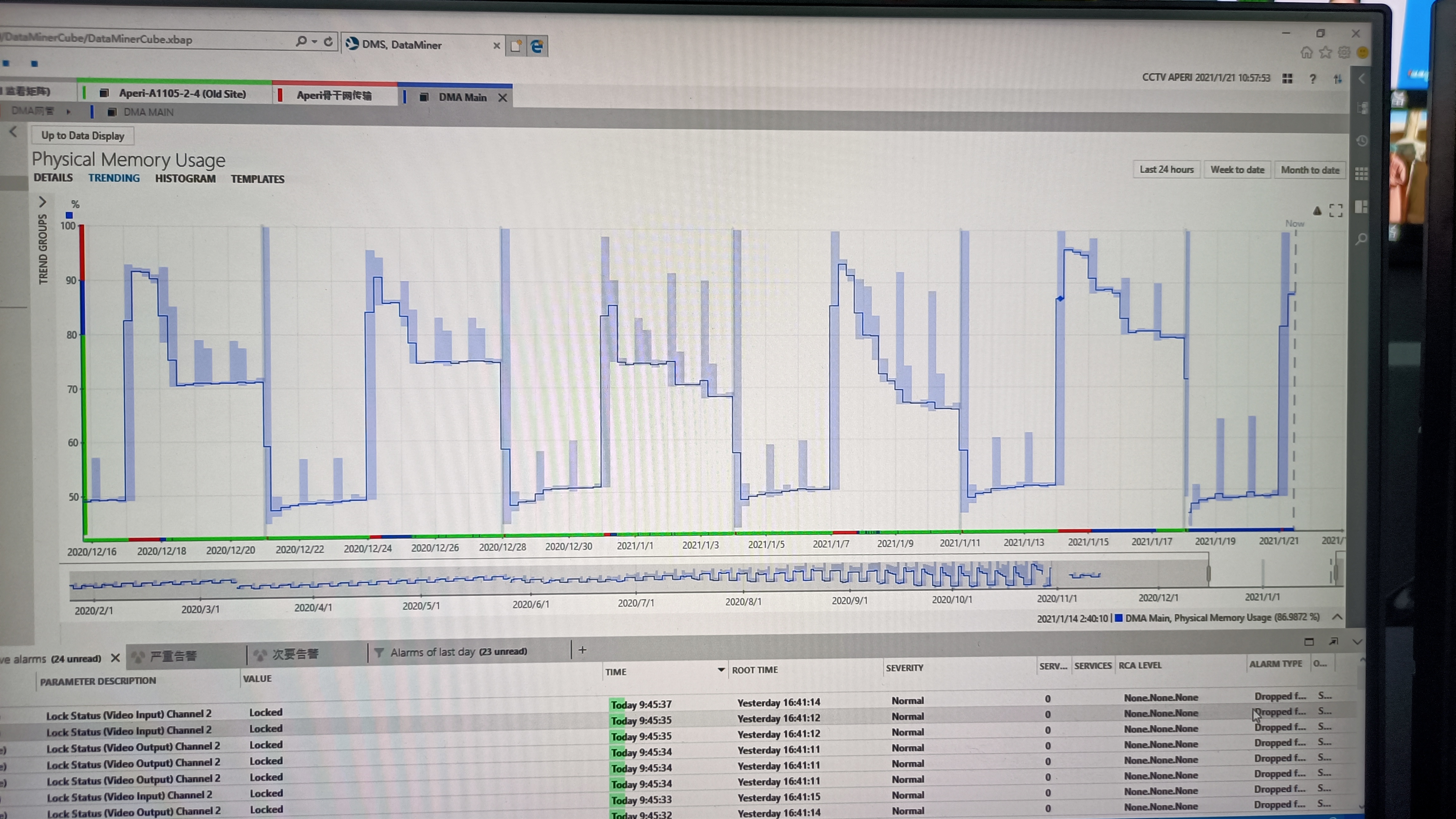
Another thing is the pattern of Cassandra related memory surge is repeating with fix pattern along a 7-days week pattern, is it normal? are there any scheduled Cassandra self-initiated process built-in cassandra PKG?
does this pattern reflect any potnetial crisis?
In addition to Toon's answer:
- The pattern shown on the trend graph above tends to occur in failover setups. The cause is that in failover setups a repair operation is running on a weekly schedule. This is Cassandra's natural behavior that after the repair it doesn't release the memory it allocated, and memory usage stays high until the compaction operation is triggered and successfully finished.
- This is not an issue, but a specific Cassandra behavior which has to be taken into account.
- Normally, this shouldn't have impact on other processes, since Windows should be able to push Cassandra's working set to Page file to free up the physical memory.
- Possible workaround: adjust the compaction and repair schedule so that compaction runs shortly after the repair finishes. Take caution not to run Compaction and Repair simultaneously.
- Possible workaround: Move Cassandra to an external server to prevent competing for memory between Cassandra and other processes.
- Strongly advised against: restarting Cassandra to free up the memory. This causes more harm than good. Possible outcomes are: data loss or corruption, failover going out of sync, compaction chronically failing and eventually running out of disk space.