I have a Dataminer system that the Cassandra snapshots are not being deleted on the time trace table. This causes the file explorer to represent a time trace folder of over 80GB. Drilling down, I notice the snapshot folder inside this table is showing 68GB(5 snapshot folders of around 14GB each). I was under the assumption that a snapshot is only a reference to this memory and not holding actual space as when I check the size in node tool these snapshots are not containing any size.
My question is - Is this related to my backups failing on this server because it is indicating we are out of space, when running the windirstat I can only see the time trace snapshots taking up most of the HD?
The timetrace table is only around 13GB without snapshots.
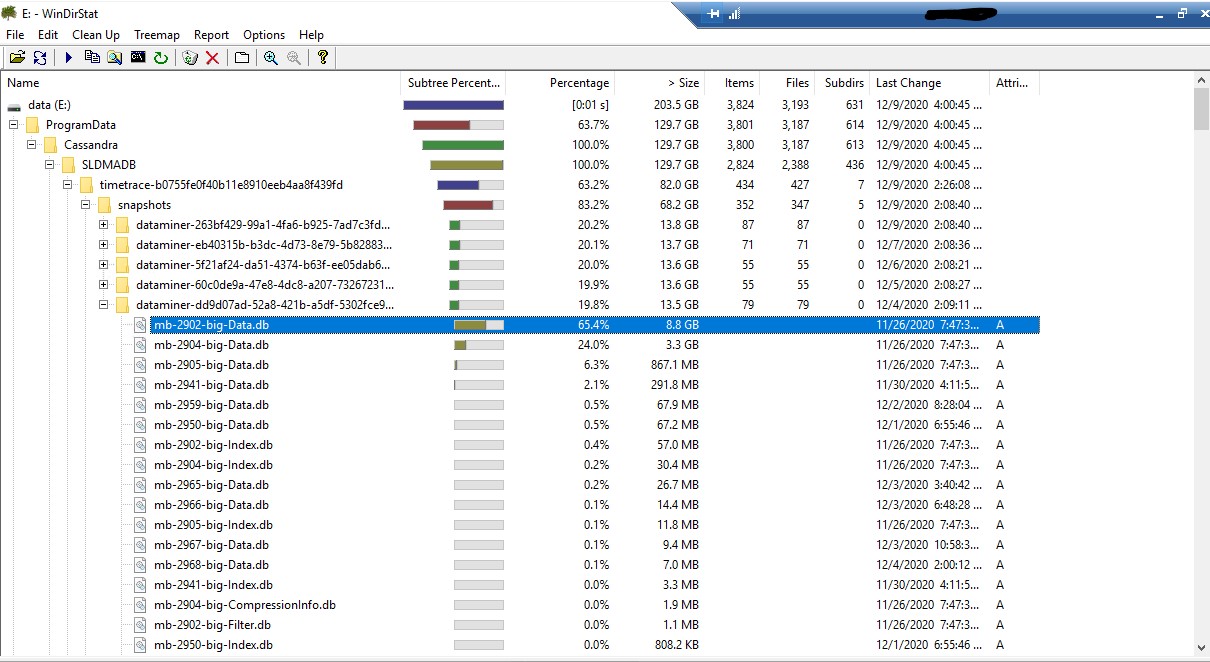
I am in the process of manually clearing the snapshots and figuring out why they aren't being cleared on a separate note.
Hi Ryan,
Probably you will find entries in the log files of Cassandra mentioning that it was not able to delete the snapshots.
E.g. WARN [RMI TCP Connection(298)-127.0.0.1] 2019-04-23 20:01:33,328 SnapshotDeletingTask.java:43 - Failed to delete snapshot [C:\ProgramData\Cassandra\SLDMADB\data-47e9f990bfc811e7823dab7ff8019ae2\snapshots\dataminer-307c274c-5470-4ee7-837b-39bb95ce534c]. Will retry after further sstable deletions. Folder will be deleted on JVM shutdown or next node restart on crash.
There is a known problem problem for Cassandra running on Cassandra that prevents snapshots to be deleted. Due to the way Windows file system and snapshots work, it is possible that some of the snapshots can't be deleted. Cassandra could still have a file handle open. When this occurs, the error above will be shown and Cassandra will eventually delete it (once the sstable is compacted away, or after a Cassandra restart).
Cassandra creates hardlinks to manage the backups. this means the data is saved once on disk, and has multiple references to it. In essence they should only take the amount of space once (the listsnapshots will tell you the truesize of the snapshot ). It is not sure how windows handles these calculations (and windirstats), if they measure them twice, or not.
In the end, Cassandra will fail eventually on deleting snapshots and will keep retrying, but it may take multiple compactions until it finally manages to delete the snapshots. If space is really an issue and you need to get rid of the snapshot, you can always quickly reboot the Cassandra after doing a clearsnaphot (this will 100% definitely, no exception delete all snapshots).
Let us know if this would not solve your problem