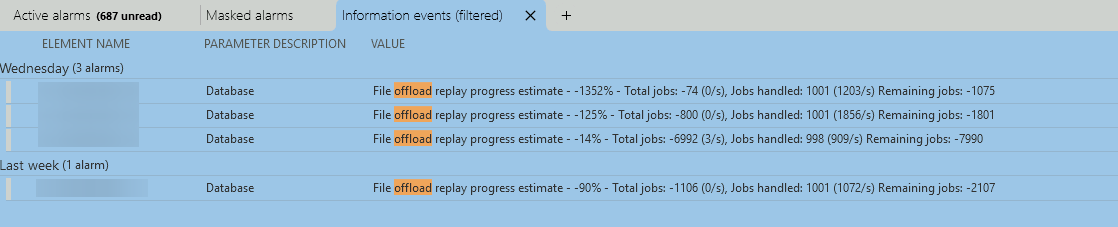
I noticed recently the following information events related to “Database – file offload replay progress estimate”. This is on a DataMiner cluster with external Cassandra and Elasticsearch cluster databases. Does anybody know what these information events actually mean and how to interpret them. Any investigation or follow-up actions needed based on these?
Koen Bouckhout [SLC] [DevOps Advocate] Selected answer as best
When the database is down or unreachable, DataMiner will fallback to ‘offload’ the data to files on its hard disk. When the database eventually is reachable again, DataMiner will try to save this data to the database by ‘replaying’ the offloaded files. I suspect this is what you’re seeing in the information events.
Koen Bouckhout [SLC] [DevOps Advocate] Selected answer as best
With that being said, looks like some of the counters got mixed up causing these high percentages.