Hi Dojo,
Are there some default thresholds that we can define for the Maximum Partition Size in the Apache Cassandra Cluster Monitor connector?
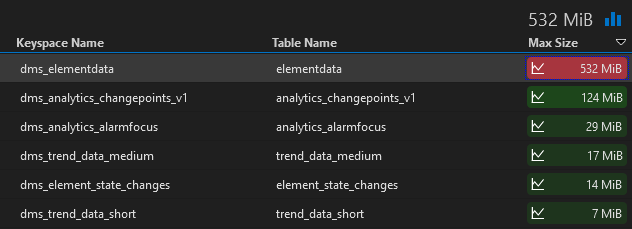
In my case table elementdata throws an critical alarm because the value is greater than 500 MiB. Is this a valid alarm or should I adapt my thresholds?
Hi Jens,
The recommendation is to stay below 200MB for performance reasons. If you have a powerful server and lots of memory, you might be less concerned about going over it.
In your case, you have at least one partition of 532MB in elementdata table (saved parameters). With the current DataMiner versions all the saved parameters are stored in one partition in the elementdata table. This is mainly to be able to retrieve all saved data with one query when the element is restarted. This means that we have a limitation on how many parameters we can save and how frequently we can update them in one element. There are discussions to split that partition into multiple ones to have the ability to store more saved parameters into one element.
There should be no immediate issue in running Cassandra with large partitions (assuming they don't exceed 2G), but you will notice that systems without large partitions will be much more performant and much more responsive. The recommendation would be to evaluate what element/protocol is causing for the large partitions avoiding having that many saved parameters or updates on saved parameters in your element/protocol.
Most seen cases are:
- Tables that have rows that are continuously being added/removed (could be a hidden table).
Solution: Make the table volatile if possible (keys and display keys are saved by default). - Values that are saved change continuously.
Solution: Remove the saved option (values that change continuously should not be saved). - Tables that grow indefinitely.
Solution: Implement a safety to keep the number of rows in a table under control.
If you don't know which element(s) are causing the large partitions then you might need to analyze the sstables on the node with large paritions. A tool that I have been using for this: GitHub - instaclustr/cassandra-sstable-tools: Tools for working with sstables