For Mysql the average row size is somewhere between 100B and 200B as most rows are in the data_ .. and data_avg_.. tables
How does this compare to cassandra? Can somebody share a average rowsize on cassandra?
Or similar question does anybody have an idea how the number of row writes/s on mysql compare to the number of row writes/s on cassandra (not including the replication) before and after migration
Hi Gert,
There is no way to say with certainty that a table of 1G in MySQL will be 2G in Cassandra. Cassandra does not work like MySQL, it will put all incoming data on disk and will trigger compaction (to order/place data on disk more efficiently). The below screenshot gives you an idea of what this should look like for disk usage. Knowing how much space Cassandra will take on a disk will depend on a number of things. Another thing to know is that in MySQL, there is a restraint on time and the number of rows for your data. It could be that if you configured to keep alarms/trend data for one year, you actually only have one month of data because you are reaching the row limit. In Cassandra, we don't have that restraint on the number of rows. Therefore, it could be that for one customer a MySQL system goes from 4G to 8G and for another, it goes from 50G to 500G.
Assuming you are moving towards the Cassandra/Elastic Cluster architecture where you have one Cassandra and Elastic cluster for your complete DMS. For the average trending (stored in Cassandra), we can give you an idea as this is the easiest to predict (fixed intervals to store it in DB). All have roughly 100B/entry (if you have large keys for your tables it might be more). The trend_data_short (5min) will be roughly 1MB/parameter (with a default TTL of 1 month). The trend_data_medium (1h) will be roughly 1MB/parameter (with a default TTL of 1 year). The trend_data_long (1d) will be roughly 40kB/parameter (with a default TTL of 1 year). For Real-time trending, it really depends on how fast your parameters are updating, but you can make an estimation if you know what parameters you are trending and how frequent they will update. The above should be an overestimation assuming that your trend data is being compacted correctly. Keep in mind that you also have other data in Cassandra such as saved parameters.
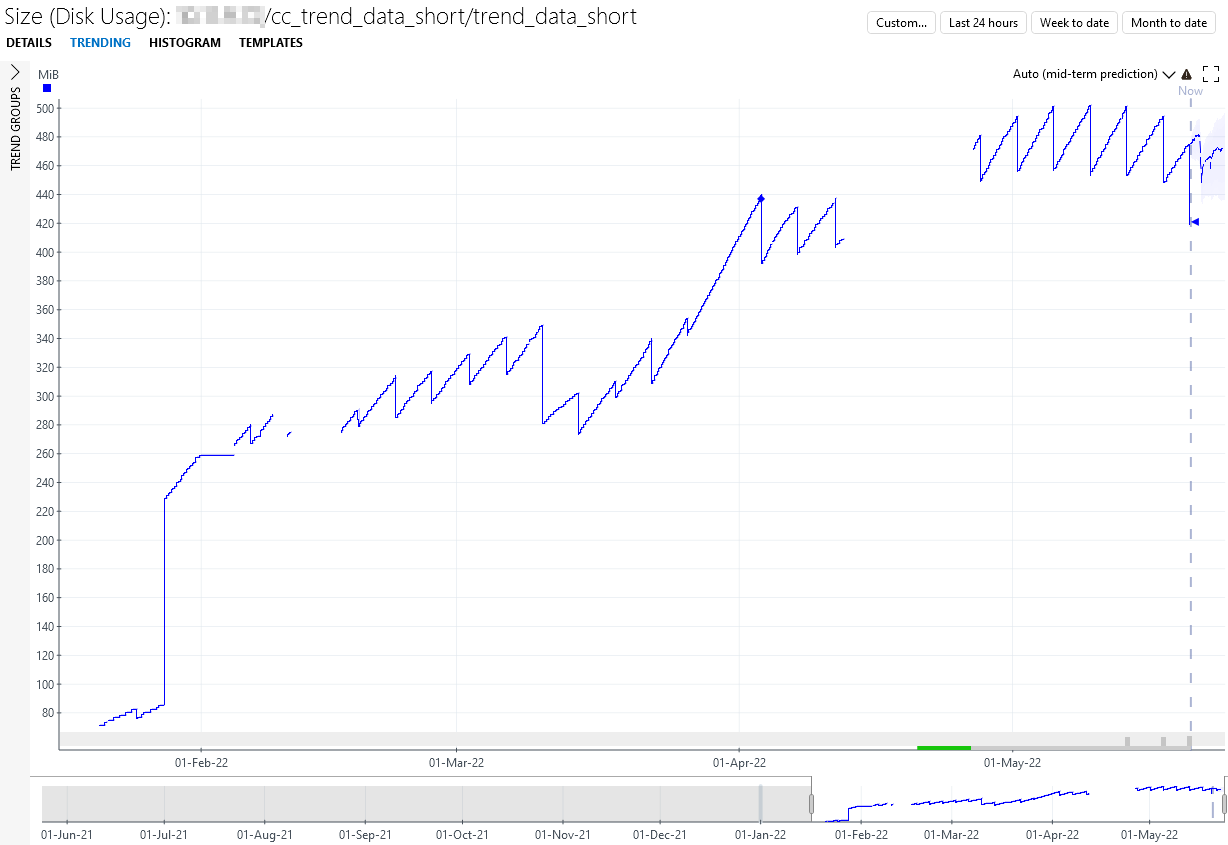
Figure: The disk usage of the trend_data_short (5min records) for one node in a three-node Cassandra cluster. The gaps in the trend are because the monitoring was not enabled during that time. This trend graph is given by the Apache Cassandra Cluster Monitor connector.
Hi Gert,
Maybe this was not completely clear in my answer, but the 100B/entry means 100B for every row in the Cassandra DB (for trend data). If you enable average trending for a parameter it will automatically store 5min, 1h and day records towards the DB. And of course, this means that every 5min, every hour and every day a record for that parameter will be written towards DB. The default TTLs are mentioned in the above answer, so you can expect after the TTL that data will expire at the same rate as it comes in.
Thank you for your answer but my question is not about database size but about row size.
We are looking at aws for example they are charging $/m rows inserted and $/m rows ttl deleted. Currently the rows inserted are basicaly key, timestamp, value.
Is that the same for cassandra or are you storing for example timestamp { key1=value1, key2=value2…}
As that would be more efficient and less costly