Hi,
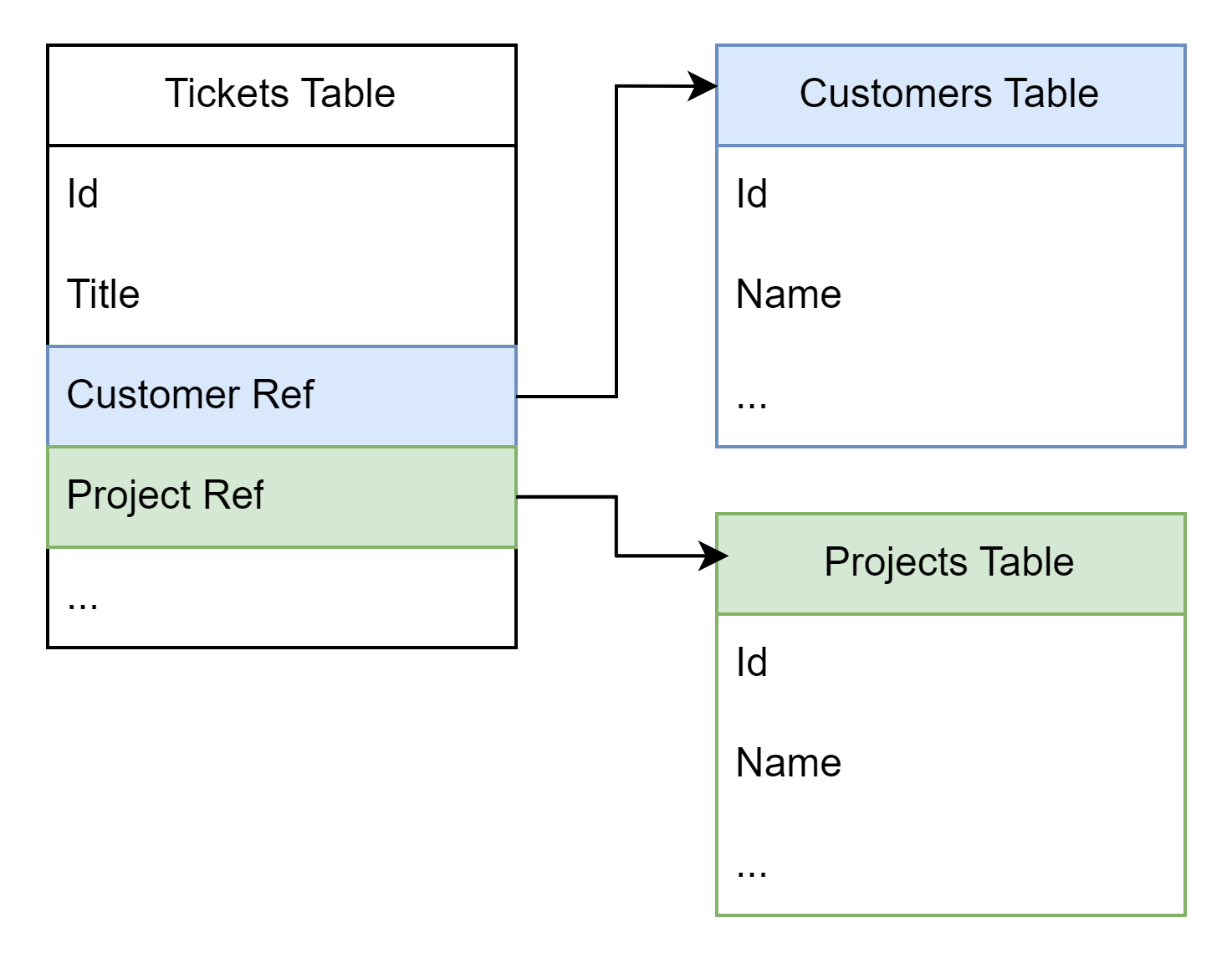
I have a simple db structure in DOM that holds a massive number of items.
Can you provide best practices and perhaps example on how to construct my GQI query in a low code app in order to have the best performance possible?
In the end I would like to see a table that holds
- all Tickets with any status Status(*) except “Closed”
- per row, the Customer Name
- per row, the Project Name
(*) Status is a column in the Tickets Table, I forgot to add it in the drawing.
Hi Mieke,
Preamble: especially when dealing with a “massive number of items” that need to be joined, more often than not the best performance can only be achieved by implementing your own dedicated ad hoc data source, but we are constantly improving GQI to get as close as possible with the built-in tools.
Let’s assume you cannot spend time on creating a new ad hoc data source.
To know how best to structure your query, it helps to understand how the join operation in GQI works exactly.
How the join operator works
When you add a join operation on your main query (let’s call it query A) in order to join with another query (call it query B), the following happens when displaying in a table:
- Start executing query A
- Start executing query B
- Fetch all rows of query B
- Store the rows of query B in memory indexed on the cell values used to join
- Start fetching rows of query A as necessary (i.e. lazy loaded)
For each row of query A:- Find matching rows of query B
- Create a new rows for A and B stitched together
This is what we call the prefetch strategy, since all rows from query B need to be fetched before any result can be returned.
Applied to your use case
I’ll assume the tickets table is the only one with a really massive number of items (millions) vs. the Customers/Project table (thousands).
Then you’d want to structure your query like this:
- Get tickets
- Filter on Status
- Join left on
- Get customers
- Join left on
- Get projects
With the best practice rules being:
- Start by querying the largest data source (this one will be lazy loaded) and later join on the smaller data source (these will need to be prefetched entirely)
- Filter as soon as possible
Note: in this basic scenario, even if the filter would be added later, GQI would still be able to automatically optimize the filter.
Final notes:
- Applying a sort operator can change how the join operator operates.
GQI will do a best-effort to find the most optimal approach while maintaining the desired row order.
For example: sorting on the Customer Name would result in the following equivalent query structure. Notice that your Tickets table here needs to be prefetched regardless:- Get customers
- Sort by Name
- Join right on
- Get tickets
- Filter on Status
- Join left on
- Get projects
- The join operation can also work in a row-by-row strategy as opposed to the aforementioned prefetch strategy (see DataMiner Docs: Join) which can be more performant in one-to-one or one-to-many scenarios where the rows to join can easily be partitioned.
This is currently not applicable to your use case; however, we have a feature on the roadmap that can employ a similar strategy that would be applicable here.