Hi,
If we need to verify the internal calculations done by Dataminer when determining the smart baseline value for a given parameter, specially for the option ‘daily pattern deviation’, what do we need to do?
The Help states that with the averaged 15-minutes trend points, a polynomial regression is applied. What is the polynomial degree? Applied to which points exactly? When is then the smart baseline read from the polynomial function?
Would it be possible to describe the complete algorithm so we can compute the expected values ourselves having as an input just the trending values of the respective parameter?
Thanks in advance.
Hello Paulo,
I opened the code and investigated how the smart baseline is calculated in the case of a daily pattern deviation, assuming you do not select “handle weekend days separately”.
The first thing to note is that a day consists of 288 five minute intervals, namely 0h00 until 0h05, 0h05 until 0h10,….,23h55 until 0h. For each of these intervals, the algorithm tries to figure out the typical value of the parameter during that interval. To do this, the algorithm fetches the last week of 5’ averages from the database. Then, for each of the aforementioned five minute intervals, it checks the value of the parameter during that interval on Monday, Tuesday,… Sunday and it takes the median M of these 7 values.
After this, we are left with the following information:

Every 15 minutes, DataMiner will check which baseline value to use for the upcoming 15 minutes. In order to this, we could just use this table. So, if during the interval 0h10-0h15, DataMiner wants to check which baseline it should use for the upcoming 15 minutes, just use M2 as the baseline. The downside of this method however is that keeping this table requires some memory, definitely for systems that have many parameters with smart baseline enabled. This is why the algorithm is going to try and summarize the information in this table by doing a polynomial regression of degree 8.
To explain this (I know you know Paulo, but for anybody else reading this), let me note that a polynomial of degree 8 is a function described by 9 numbers
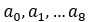
which maps any number t to
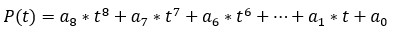
Ideally, what we would like is to find the 9 coefficients a in such a way that when you fill in an index t=i, that
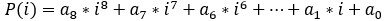
equals the i’th median Mi. If you can do that, then you don’t have to remember all the median values M anymore (this saves memory) and you can just remember the 9 coefficients instead.
Unfortunately, in most cases this is not possible, so instead the algorithm is going to try to find the a’s in such a way that P(i) is as good of an approximation as possible for the i’th median Mi.
The above procedure (fetching a week of data and calculating the aj) is repeated once per day for each parameter with a smart baseline enabled, typically around midnight.
Apart from that, every 15 minutes, DataMiner will calculate which baseline value to use for the next 15 minutes. So, assume, it was now 15’ ago since our last calculation. Then DataMiner does the following:
1) Look at the current time: what is the corresponding index i?
e.g. if it is 10h02, it lies in the interval 10h until 10h05 which has index i=120.
2) As a baseline, use the number P(i)
e.g. at 10h02, DataMiner will use P(120) as baseline value to decide when to trigger alarms.
I hope this explanation clarifies how the smart baseline works. If you have any further questions, please don’t hesitate to reach out!
Regarding the pictures you posted, thank you, Paulo, for sending me the datasets. I will look into these today and get back to you.
Hello Paulo,
thanks for your comment and the datasets you provided!
Yeah, as we discussed yesterday, a polynomial of degree 8 might not fit the very irregular patterns, but on the other hand I do believe this approximation will be ok in a large percentage of cases as the degree is rather high. It is something I will discuss within our team and the squad responsible for this feature: it’s all a balance between saving memory and exactness and depends on how irregular the patterns are that we expect in such data. Maybe as more memory becomes available on customer systems, this modelling approach might even be omitted all together.
With regards to the datasets you sent (pictures in your post above), I ran some experiments to verify whether this degree 8 approximation could be the issue you’re experiencing. For each dataset, I first calculated the medians as displayed in the table in my previous post in this thread. This is plotted in orange.
Then, for each day, I ran the degree 8 approximation and plotted that in blue. As you see, the blue lines are rather good (but indeed not perfect) approximations of the actual medians…
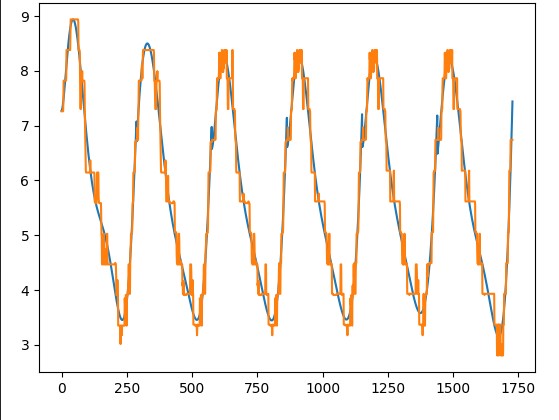
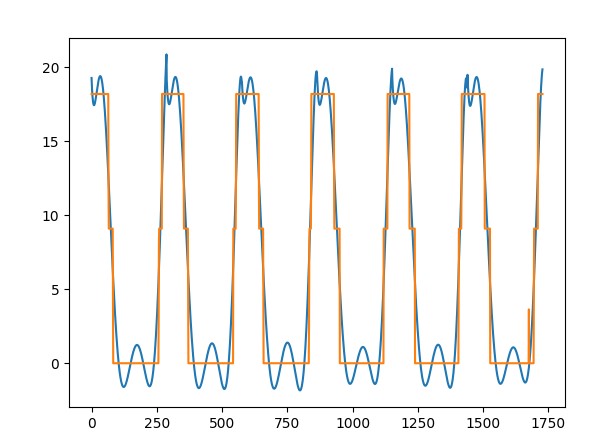
As discussed, this means that your issue must lie elsewhere. If there is anything we can help you with in that regards, don’t hesitate to reach out. I will also keep you posted on any decisions on the adaptation of the smart baseline functionality.
Thanks a lot for your question!
Dennis
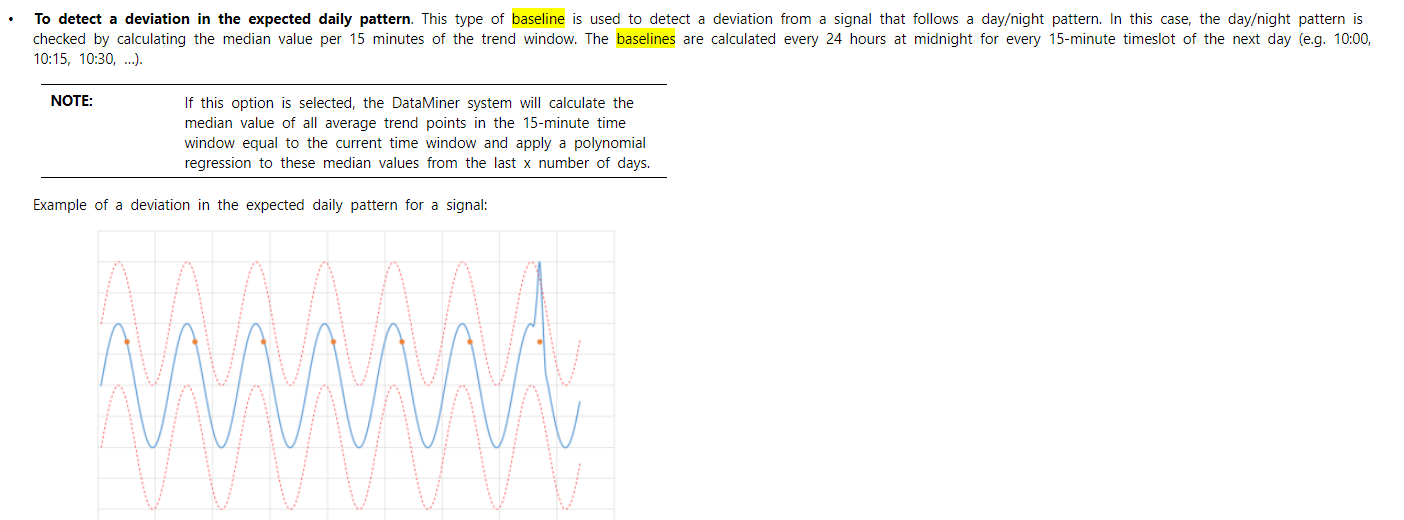
Please look at the 2 examples below, the dark-blue line is the parameter that has the smart baseline active with the daily pattern option, 7 days window and the light-blue is the smart baseline calculated by Dataminer:
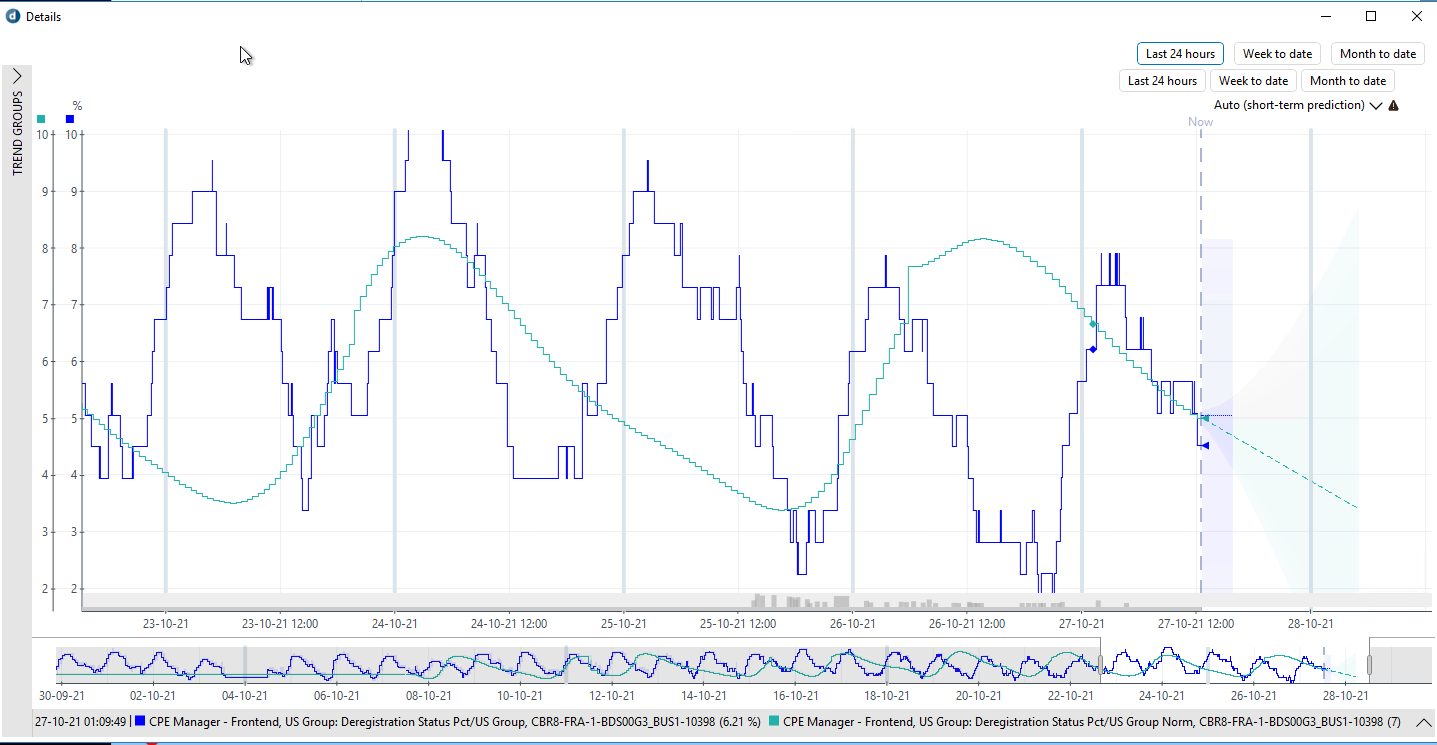
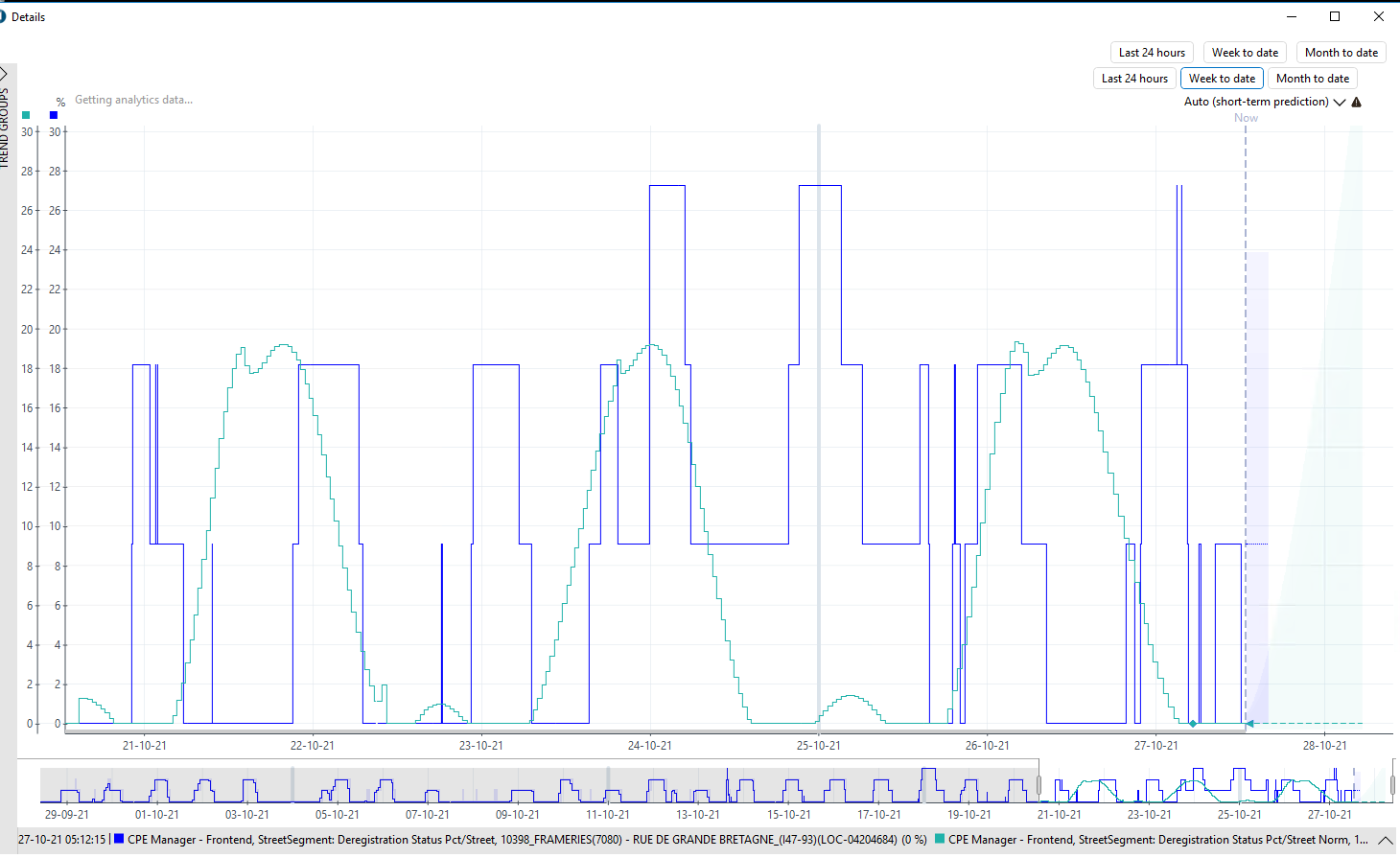
In the 1st, we can clearly identify a daily pattern which is not reflected on the calculated smart baseline.
The 2nd, even though is more difficult to identify a daily pattern, it is still there: at the evening and during the night, the parameter has higher values than during the daylight. The smart baseline could never be the one calculated.
What am I missing here?
This is release 10.1.0 CU6.
Thank you Dennis for the detailed explanation of the algorithm.
Using an 8th degree polynomial to fit a curve that has 288 different values is a bit optimistic, to say the least. Basically, you are trying to approximate the daily pattern curve with a polynomial function of only degree 8 which it may work well for regular and slow changing patterns, but for irregular and the ones changing the value very quickly, the result will be far away from the intended. I believe there is a lot of room to improve here in these calculations of the smart baselines.