Hi, please consider the following DMA architecture below:
4 VMs running DMAs configured in a cluster. Each VM is talking to its own Cassandra DB which runs on separate VMs.
The DMA cluster is communicating to ElasticSearch consisting of 4 separate VMs configured as a single cluster.
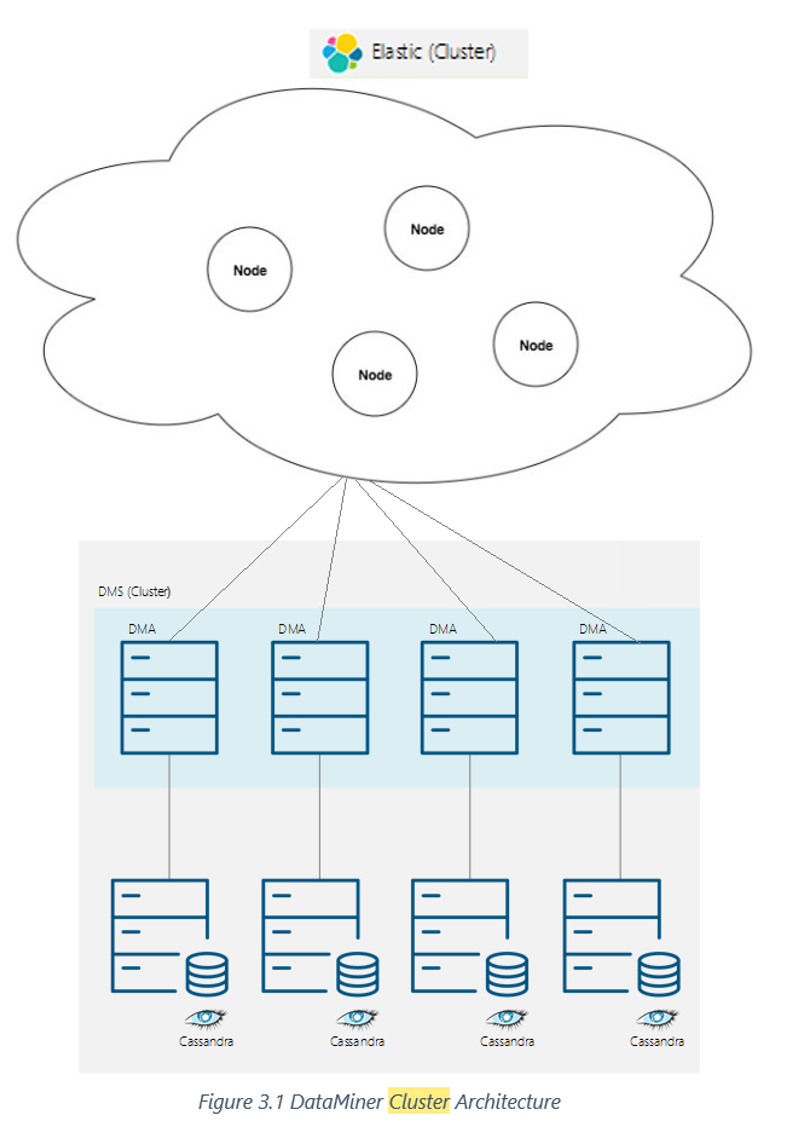
I understand that the recommended approach is to shutdown the DMA when maintenance activities needs to be carried out on its associated DB. For example if Cassandra DB #4 needs have its OS upgraded, patched and VM restarted, it is recommended to stop DMA#4.
Does this recommended approach apply to maintenance of ElasticSearch VMs as well? Or can the VMs in the ElasticSearch DB be upgraded with zero downtime from the perspective of the DMA cluster hence not requiring any of the DMAs to be shutdown?
Hi Bing,
For elasticsearch nodes, this maintenance procedure wouldn’t be needed. The elasticsearch nodes are already setup as an elasticsearch cluster where a DataMiner node actually can interface with any of the elasticsearch nodes and doesn’t necessarily need to communicate to that particular node where you are planning your maintenance on.
If you would check the db.xml configuration file on the DMA, you should spot multiple elasticsearch node IP’s in the elasticsearch configuration part of the db.xml file. If your DMA notices that the node its communicating with becomes unavailable, it will automatically switch communication over to any other of the available node IP addresses listed.
So as long as you run your ES node maintenance on one node at a time, your DMA cluster can remain operational without a need of stopping DataMiner agent nodes.
For the legacy cassandra architecture where each DMA has its own single standalone cassandra node as local database, you are indeed correct that you will need to shut down the DMA node associated with the cassandra node you want to temporarily interrupt to run your maintenance on. But in case this DMA is part of a failover setup, or that its making use of the newly introduced cassandra cluster local database feature (in both those scenario’s, cassandra nodes are running in a cluster configuration). Then you should see a similar approach where the DMA’s have multiple cassandra node IP’s configured as contact points. In that case the DMA will automatically connect to a different cassandra node in case it notices a loss of communication.
Hopefully this sheds some light on the matter.
Hi Bruno,
In that case your entire elasticsearch cluster would be down when executing the maintenance and the DataMiner cluster (all DMA’s connecting to this elasticsearch node) would detect a loss of connection. We would expect the DMA’s to start locally caching the data in offload files until the ES cluster is operational and available again.
Appreciate your view on this matter Jeroen. Thanks!
What if my DMS is just using a single elasticsearch node?