We have alams on a failover pair (part of a large cluster) for the Cassandra Sync and have tried restarting the Cassandra service, and rebooting the DMA.

When running nodetool the Host ID replies with “null” which I suspect is the issue.
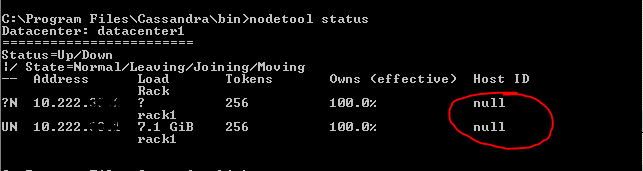
Has anyone seen this before?
Thanks
Hi, see config files below. KR Paul
Hi Paul,
From your ‘nodetool status’ message you can see that the first node (from which you are probably running the ‘nodetool status’ cmd) is having a status ?N and this means the node is not started Up. The other node is UN (Up and Normal), probably ‘nodetool status’ on the other node will give you a different result. Can you share that result (you can edit your answer as well).
My first step would be to look into the logging of Cassandra on both nodes to understand what is going wrong. As most likely this is from a Failover setup (both nodes should have all data to have redundancy), you could start focussing on one node to get it started and then focus on the other node. If you are hosting DM and Cassandra on the same OS, it could be that DM is continuously trying to start Cassandra. You can disable the service from the services in Windows if you want to prevent DM from starting Cassandra or you can also stop DM on that node.
Hi Paul,
As far as the issue is located on your environment, it will need a detailed investigation, so another option is to send the question to techsupport@skyline.be
They will need the SLLogCollector package from both nodes to start the investigation, so you can already already extract them (screenshot below), normally they will also inform a location where you can upload the files
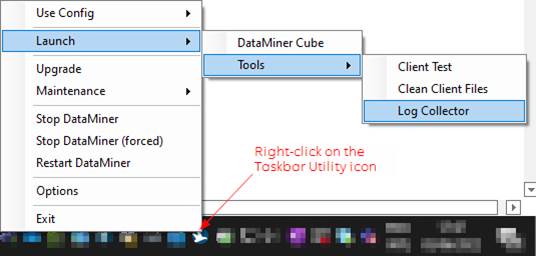
When Log Collector starts, use default settings and press “Start”. The package will be saved on your desktop:

Off line agent
# Cassandra storage config YAML
# NOTE:
# See http://wiki.apache.org/cassandra/StorageConfiguration for
# full explanations of configuration directives
# /NOTE
# The name of the cluster. This is mainly used to prevent machines in
# one logical cluster from joining another.
cluster_name: ‘DMS’
# This defines the number of tokens randomly assigned to this node on the ring
# The more tokens, relative to other nodes, the larger the proportion of data
# that this node will store. You probably want all nodes to have the same number
# of tokens assuming they have equal hardware capability.
#
# If you leave this unspecified, Cassandra will use the default of 1 token for legacy compatibility,
# and will use the initial_token as described below.
#
# Specifying initial_token will override this setting on the node’s initial start,
# on subsequent starts, this setting will apply even if initial token is set.
#
# If you already have a cluster with 1 token per node, and wish to migrate to
# multiple tokens per node, see http://wiki.apache.org/cassandra/Operations
num_tokens: 256
# Triggers automatic allocation of num_tokens tokens for this node. The allocation
# algorithm attempts to choose tokens in a way that optimizes replicated load over
# the nodes in the datacenter for the replication strategy used by the specified
# keyspace.
#
# The load assigned to each node will be close to proportional to its number of
# vnodes.
#
# Only supported with the Murmur3Partitioner.
# allocate_tokens_for_keyspace: KEYSPACE
# initial_token allows you to specify tokens manually. While you can use # it with
# vnodes (num_tokens > 1, above) — in which case you should provide a
# comma-separated list — it’s primarily used when adding nodes # to legacy clusters
# that do not have vnodes enabled.
# initial_token:
# See http://wiki.apache.org/cassandra/HintedHandoff
# May either be “true” or “false” to enable globally
hinted_handoff_enabled: true
# When hinted_handoff_enabled is true, a black list of data centers that will not
# perform hinted handoff
#hinted_handoff_disabled_datacenters:
# – DC1
# – DC2
# this defines the maximum amount of time a dead host will have hints
# generated. After it has been dead this long, new hints for it will not be
# created until it has been seen alive and gone down again.
max_hint_window_in_ms: 10800000 # 3 hours
# Maximum throttle in KBs per second, per delivery thread. This will be
# reduced proportionally to the number of nodes in the cluster. (If there
# are two nodes in the cluster, each delivery thread will use the maximum
# rate; if there are three, each will throttle to half of the maximum,
# since we expect two nodes to be delivering hints simultaneously.)
hinted_handoff_throttle_in_kb: 1024
# Number of threads with which to deliver hints;
# Consider increasing this number when you have multi-dc deployments, since
# cross-dc handoff tends to be slower
max_hints_delivery_threads: 2
# Directory where Cassandra should store hints.
# If not set, the default directory is $CASSANDRA_HOME/data/hints.
# hints_directory: /var/lib/cassandra/hints
# How often hints should be flushed from the internal buffers to disk.
# Will *not* trigger fsync.
hints_flush_period_in_ms: 10000
# Maximum size for a single hints file, in megabytes.
max_hints_file_size_in_mb: 128
# Compression to apply to the hint files. If omitted, hints files
# will be written uncompressed. LZ4, Snappy, and Deflate compressors
# are supported.
#hints_compression:
# – class_name: LZ4Compressor
# parameters:
# –
# Maximum throttle in KBs per second, total. This will be
# reduced proportionally to the number of nodes in the cluster.
batchlog_replay_throttle_in_kb: 1024
# Authentication backend, implementing IAuthenticator; used to identify users
# Out of the box, Cassandra provides org.apache.cassandra.auth.{AllowAllAuthenticator,
# PasswordAuthenticator}.
#
# – AllowAllAuthenticator performs no checks – set it to disable authentication.
# – PasswordAuthenticator relies on username/password pairs to authenticate
# users. It keeps usernames and hashed passwords in system_auth.credentials table.
# Please increase system_auth keyspace replication factor if you use this authenticator.
# If using PasswordAuthenticator, CassandraRoleManager must also be used (see below)
authenticator: PasswordAuthenticator
# Authorization backend, implementing IAuthorizer; used to limit access/provide permissions
# Out of the box, Cassandra provides org.apache.cassandra.auth.{AllowAllAuthorizer,
# CassandraAuthorizer}.
#
# – AllowAllAuthorizer allows any action to any user – set it to disable authorization.
# – CassandraAuthorizer stores permissions in system_auth.permissions table. Please
# increase system_auth keyspace replication factor if you use this authorizer.
authorizer: AllowAllAuthorizer
# Part of the Authentication & Authorization backend, implementing IRoleManager; used
# to maintain grants and memberships between roles.
# Out of the box, Cassandra provides org.apache.cassandra.auth.CassandraRoleManager,
# which stores role information in the system_auth keyspace. Most functions of the
# IRoleManager require an authenticated login, so unless the configured IAuthenticator
# actually implements authentication, most of this functionality will be unavailable.
#
# – CassandraRoleManager stores role data in the system_auth keyspace. Please
# increase system_auth keyspace replication factor if you use this role manager.
role_manager: CassandraRoleManager
# Validity period for roles cache (fetching granted roles can be an expensive
# operation depending on the role manager, CassandraRoleManager is one example)
# Granted roles are cached for authenticated sessions in AuthenticatedUser and
# after the period specified here, become eligible for (async) reload.
# Defaults to 2000, set to 0 to disable caching entirely.
# Will be disabled automatically for AllowAllAuthenticator.
roles_validity_in_ms: 2000
# Refresh interval for roles cache (if enabled).
# After this interval, cache entries become eligible for refresh. Upon next
# access, an async reload is scheduled and the old value returned until it
# completes. If roles_validity_in_ms is non-zero, then this must be
# also.
# Defaults to the same value as roles_validity_in_ms.
# roles_update_interval_in_ms: 2000
# Validity period for permissions cache (fetching permissions can be an
# expensive operation depending on the authorizer, CassandraAuthorizer is
# one example). Defaults to 2000, set to 0 to disable.
# Will be disabled automatically for AllowAllAuthorizer.
permissions_validity_in_ms: 2000
# Refresh interval for permissions cache (if enabled).
# After this interval, cache entries become eligible for refresh. Upon next
# access, an async reload is scheduled and the old value returned until it
# completes. If permissions_validity_in_ms is non-zero, then this must be
# also.
# Defaults to the same value as permissions_validity_in_ms.
# permissions_update_interval_in_ms: 2000
# Validity period for credentials cache. This cache is tightly coupled to
# the provided PasswordAuthenticator implementation of IAuthenticator. If
# another IAuthenticator implementation is configured, this cache will not
# be automatically used and so the following settings will have no effect.
# Please note, credentials are cached in their encrypted form, so while
# activating this cache may reduce the number of queries made to the
# underlying table, it may not bring a significant reduction in the
# latency of individual authentication attempts.
# Defaults to 2000, set to 0 to disable credentials caching.
credentials_validity_in_ms: 2000
# Refresh interval for credentials cache (if enabled).
# After this interval, cache entries become eligible for refresh. Upon next
# access, an async reload is scheduled and the old value returned until it
# completes. If credentials_validity_in_ms is non-zero, then this must be
# also.
# Defaults to the same value as credentials_validity_in_ms.
# credentials_update_interval_in_ms: 2000
# The partitioner is responsible for distributing groups of rows (by
# partition key) across nodes in the cluster. You should leave this
# alone for new clusters. The partitioner can NOT be changed without
# reloading all data, so when upgrading you should set this to the
# same partitioner you were already using.
#
# Besides Murmur3Partitioner, partitioners included for backwards
# compatibility include RandomPartitioner, ByteOrderedPartitioner, and
# OrderPreservingPartitioner.
#
partitioner: org.apache.cassandra.dht.Murmur3Partitioner
# Directories where Cassandra should store data on disk. Cassandra
# will spread data evenly across them, subject to the granularity of
# the configured compaction strategy.
# If not set, the default directory is $CASSANDRA_HOME/data/data.
data_file_directories:
– E:\ProgramData\Cassandra
# commit log. when running on magnetic HDD, this should be a
# separate spindle than the data directories.
# If not set, the default directory is $CASSANDRA_HOME/data/commitlog.
# commitlog_directory: /var/lib/cassandra/commitlog
# policy for data disk failures:
# die: shut down gossip and client transports and kill the JVM for any fs errors or
# single-sstable errors, so the node can be replaced.
# stop_paranoid: shut down gossip and client transports even for single-sstable errors,
# kill the JVM for errors during startup.
# stop: shut down gossip and client transports, leaving the node effectively dead, but
# can still be inspected via JMX, kill the JVM for errors during startup.
# best_effort: stop using the failed disk and respond to requests based on
# remaining available sstables. This means you WILL see obsolete
# data at CL.ONE!
# ignore: ignore fatal errors and let requests fail, as in pre-1.2 Cassandra
disk_failure_policy: stop
# policy for commit disk failures:
# die: shut down gossip and Thrift and kill the JVM, so the node can be replaced.
# stop: shut down gossip and Thrift, leaving the node effectively dead, but
# can still be inspected via JMX.
# stop_commit: shutdown the commit log, letting writes collect but
# continuing to service reads, as in pre-2.0.5 Cassandra
# ignore: ignore fatal errors and let the batches fail
commit_failure_policy: stop
# Maximum size of the native protocol prepared statement cache
#
# Valid values are either “auto” (omitting the value) or a value greater 0.
#
# Note that specifying a too large value will result in long running GCs and possbily
# out-of-memory errors. Keep the value at a small fraction of the heap.
#
# If you constantly see “prepared statements discarded in the last minute because
# cache limit reached” messages, the first step is to investigate the root cause
# of these messages and check whether prepared statements are used correctly –
# i.e. use bind markers for variable parts.
#
# Do only change the default value, if you really have more prepared statements than
# fit in the cache. In most cases it is not neccessary to change this value.
# Constantly re-preparing statements is a performance penalty.
#
# Default value (“auto”) is 1/256th of the heap or 10MB, whichever is greater
prepared_statements_cache_size_mb:
# Maximum size of the Thrift prepared statement cache
#
# If you do not use Thrift at all, it is safe to leave this value at “auto”.
#
# See description of ‘prepared_statements_cache_size_mb’ above for more information.
#
# Default value (“auto”) is 1/256th of the heap or 10MB, whichever is greater
thrift_prepared_statements_cache_size_mb:
# Maximum size of the key cache in memory.
#
# Each key cache hit saves 1 seek and each row cache hit saves 2 seeks at the
# minimum, sometimes more. The key cache is fairly tiny for the amount of
# time it saves, so it’s worthwhile to use it at large numbers.
# The row cache saves even more time, but must contain the entire row,
# so it is extremely space-intensive. It’s best to only use the
# row cache if you have hot rows or static rows.
#
# NOTE: if you reduce the size, you may not get you hottest keys loaded on startup.
#
# Default value is empty to make it “auto” (min(5% of Heap (in MB), 100MB)). Set to 0 to disable key cache.
key_cache_size_in_mb:
# Duration in seconds after which Cassandra should
# save the key cache. Caches are saved to saved_caches_directory as
# specified in this configuration file.
#
# Saved caches greatly improve cold-start speeds, and is relatively cheap in
# terms of I/O for the key cache. Row cache saving is much more expensive and
# has limited use.
#
# Default is 14400 or 4 hours.
key_cache_save_period: 14400
# Number of keys from the key cache to save
# Disabled by default, meaning all keys are going to be saved
# key_cache_keys_to_save: 100
# Row cache implementation class name.
# Available implementations:
# org.apache.cassandra.cache.OHCProvider Fully off-heap row cache implementation (default).
# org.apache.cassandra.cache.SerializingCacheProvider This is the row cache implementation availabile
# in previous releases of Cassandra.
# row_cache_class_name: org.apache.cassandra.cache.OHCProvider
# Maximum size of the row cache in memory.
# Please note that OHC cache implementation requires some additional off-heap memory to manage
# the map structures and some in-flight memory during operations before/after cache entries can be
# accounted against the cache capacity. This overhead is usually small compared to the whole capacity.
# Do not specify more memory that the system can afford in the worst usual situation and leave some
# headroom for OS block level cache. Do never allow your system to swap.
#
# Default value is 0, to disable row caching.
row_cache_size_in_mb: 0
# Duration in seconds after which Cassandra should save the row cache.
# Caches are saved to saved_caches_directory as specified in this configuration file.
#
# Saved caches greatly improve cold-start speeds, and is relatively cheap in
# terms of I/O for the key cache. Row cache saving is much more expensive and
# has limited use.
#
# Default is 0 to disable saving the row cache.
row_cache_save_period: 0
# Number of keys from the row cache to save.
# Specify 0 (which is the default), meaning all keys are going to be saved
# row_cache_keys_to_save: 100
# Maximum size of the counter cache in memory.
#
# Counter cache helps to reduce counter locks’ contention for hot counter cells.
# In case of RF = 1 a counter cache hit will cause Cassandra to skip the read before
# write entirely. With RF > 1 a counter cache hit will still help to reduce the duration
# of the lock hold, helping with hot counter cell updates, but will not allow skipping
# the read entirely. Only the local (clock, count) tuple of a counter cell is kept
# in memory, not the whole counter, so it’s relatively cheap.
#
# NOTE: if you reduce the size, you may not get you hottest keys loaded on startup.
#
# Default value is empty to make it “auto” (min(2.5% of Heap (in MB), 50MB)). Set to 0 to disable counter cache.
# NOTE: if you perform counter deletes and rely on low gcgs, you should disable the counter cache.
counter_cache_size_in_mb:
# Duration in seconds after which Cassandra should
# save the counter cache (keys only). Caches are saved to saved_caches_directory as
# specified in this configuration file.
#
# Default is 7200 or 2 hours.
counter_cache_save_period: 7200
# Number of keys from the counter cache to save
# Disabled by default, meaning all keys are going to be saved
# counter_cache_keys_to_save: 100
# saved caches
# If not set, the default directory is $CASSANDRA_HOME/data/saved_caches.
# saved_caches_directory: /var/lib/cassandra/saved_caches
# commitlog_sync may be either “periodic” or “batch.”
#
# When in batch mode, Cassandra won’t ack writes until the commit log
# has been fsynced to disk. It will wait
# commitlog_sync_batch_window_in_ms milliseconds between fsyncs.
# This window should be kept short because the writer threads will
# be unable to do extra work while waiting. (You may need to increase
# concurrent_writes for the same reason.)
#
# commitlog_sync: batch
# commitlog_sync_batch_window_in_ms: 2
#
# the other option is “periodic” where writes may be acked immediately
# and the CommitLog is simply synced every commitlog_sync_period_in_ms
# milliseconds.
commitlog_sync: periodic
commitlog_sync_period_in_ms: 10000
# The size of the individual commitlog file segments. A commitlog
# segment may be archived, deleted, or recycled once all the data
# in it (potentially from each columnfamily in the system) has been
# flushed to sstables.
#
# The default size is 32, which is almost always fine, but if you are
# archiving commitlog segments (see commitlog_archiving.properties),
# then you probably want a finer granularity of archiving; 8 or 16 MB
# is reasonable.
# Max mutation size is also configurable via max_mutation_size_in_kb setting in
# cassandra.yaml. The default is half the size commitlog_segment_size_in_mb * 1024.
#
# NOTE: If max_mutation_size_in_kb is set explicitly then commitlog_segment_size_in_mb must
# be set to at least twice the size of max_mutation_size_in_kb / 1024
#
commitlog_segment_size_in_mb: 32
# Compression to apply to the commit log. If omitted, the commit log
# will be written uncompressed. LZ4, Snappy, and Deflate compressors
# are supported.
#commitlog_compression:
# – class_name: LZ4Compressor
# parameters:
# –
# any class that implements the SeedProvider interface and has a
# constructor that takes a Map<String, String> of parameters will do.
seed_provider:
# Addresses of hosts that are deemed contact points.
# Cassandra nodes use this list of hosts to find each other and learn
# the topology of the ring. You must change this if you are running
# multiple nodes!
– class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
# seeds is actually a comma-delimited list of addresses.
# Ex: “<ip1>,<ip2>,<ip3>”
– seeds: “10.222.33.1,10.222.33.2”
# For workloads with more data than can fit in memory, Cassandra’s
# bottleneck will be reads that need to fetch data from
# disk. “concurrent_reads” should be set to (16 * number_of_drives) in
# order to allow the operations to enqueue low enough in the stack
# that the OS and drives can reorder them. Same applies to
# “concurrent_counter_writes”, since counter writes read the current
# values before incrementing and writing them back.
#
# On the other hand, since writes are almost never IO bound, the ideal
# number of “concurrent_writes” is dependent on the number of cores in
# your system; (8 * number_of_cores) is a good rule of thumb.
concurrent_reads: 32
concurrent_writes: 32
concurrent_counter_writes: 32
# For materialized view writes, as there is a read involved, so this should
# be limited by the less of concurrent reads or concurrent writes.
concurrent_materialized_view_writes: 32
# Maximum memory to use for sstable chunk cache and buffer pooling.
# 32MB of this are reserved for pooling buffers, the rest is used as an
# cache that holds uncompressed sstable chunks.
# Defaults to the smaller of 1/4 of heap or 512MB. This pool is allocated off-heap,
# so is in addition to the memory allocated for heap. The cache also has on-heap
# overhead which is roughly 128 bytes per chunk (i.e. 0.2% of the reserved size
# if the default 64k chunk size is used).
# Memory is only allocated when needed.
# file_cache_size_in_mb: 512
# Flag indicating whether to allocate on or off heap when the sstable buffer
# pool is exhausted, that is when it has exceeded the maximum memory
# file_cache_size_in_mb, beyond which it will not cache buffers but allocate on request.
# buffer_pool_use_heap_if_exhausted: true
# The strategy for optimizing disk read
# Possible values are:
# ssd (for solid state disks, the default)
# spinning (for spinning disks)
disk_optimization_strategy: spinning
# Total permitted memory to use for memtables. Cassandra will stop
# accepting writes when the limit is exceeded until a flush completes,
# and will trigger a flush based on memtable_cleanup_threshold
# If omitted, Cassandra will set both to 1/4 the size of the heap.
# memtable_heap_space_in_mb: 2048
# memtable_offheap_space_in_mb: 2048
# Ratio of occupied non-flushing memtable size to total permitted size
# that will trigger a flush of the largest memtable. Larger mct will
# mean larger flushes and hence less compaction, but also less concurrent
# flush activity which can make it difficult to keep your disks fed
# under heavy write load.
#
# memtable_cleanup_threshold defaults to 1 / (memtable_flush_writers + 1)
# memtable_cleanup_threshold: 0.11
# Specify the way Cassandra allocates and manages memtable memory.
# Options are:
# heap_buffers: on heap nio buffers
# offheap_buffers: off heap (direct) nio buffers
# offheap_objects: off heap objects
memtable_allocation_type: heap_buffers
# Total space to use for commit logs on disk.
#
# If space gets above this value, Cassandra will flush every dirty CF
# in the oldest segment and remove it. So a small total commitlog space
# will tend to cause more flush activity on less-active columnfamilies.
#
# The default value is the smaller of 8192, and 1/4 of the total space
# of the commitlog volume.
#
# commitlog_total_space_in_mb: 8192
# This sets the amount of memtable flush writer threads. These will
# be blocked by disk io, and each one will hold a memtable in memory
# while blocked.
#
# memtable_flush_writers defaults to one per data_file_directory.
#
# If your data directories are backed by SSD, you can increase this, but
# avoid having memtable_flush_writers * data_file_directories > number of cores
#memtable_flush_writers: 1
# A fixed memory pool size in MB for for SSTable index summaries. If left
# empty, this will default to 5% of the heap size. If the memory usage of
# all index summaries exceeds this limit, SSTables with low read rates will
# shrink their index summaries in order to meet this limit. However, this
# is a best-effort process. In extreme conditions Cassandra may need to use
# more than this amount of memory.
index_summary_capacity_in_mb:
# How frequently index summaries should be resampled. This is done
# periodically to redistribute memory from the fixed-size pool to sstables
# proportional their recent read rates. Setting to -1 will disable this
# process, leaving existing index summaries at their current sampling level.
index_summary_resize_interval_in_minutes: 60
# Whether to, when doing sequential writing, fsync() at intervals in
# order to force the operating system to flush the dirty
# buffers. Enable this to avoid sudden dirty buffer flushing from
# impacting read latencies. Almost always a good idea on SSDs; not
# necessarily on platters.
trickle_fsync: false
trickle_fsync_interval_in_kb: 10240
# TCP port, for commands and data
# For security reasons, you should not expose this port to the internet. Firewall it if needed.
storage_port: 7000
# SSL port, for encrypted communication. Unused unless enabled in
# encryption_options
# For security reasons, you should not expose this port to the internet. Firewall it if needed.
ssl_storage_port: 7001
# Address or interface to bind to and tell other Cassandra nodes to connect to.
# You _must_ change this if you want multiple nodes to be able to communicate!
#
# Set listen_address OR listen_interface, not both. Interfaces must correspond
# to a single address, IP aliasing is not supported.
#
# Leaving it blank leaves it up to InetAddress.getLocalHost(). This
# will always do the Right Thing _if_ the node is properly configured
# (hostname, name resolution, etc), and the Right Thing is to use the
# address associated with the hostname (it might not be).
#
# Setting listen_address to 0.0.0.0 is always wrong.
#
# If you choose to specify the interface by name and the interface has an ipv4 and an ipv6 address
# you can specify which should be chosen using listen_interface_prefer_ipv6. If false the first ipv4
# address will be used. If true the first ipv6 address will be used. Defaults to false preferring
# ipv4. If there is only one address it will be selected regardless of ipv4/ipv6.
listen_address: 10.222.33.2
# listen_interface: eth0
# listen_interface_prefer_ipv6: false
# Address to broadcast to other Cassandra nodes
# Leaving this blank will set it to the same value as listen_address
# broadcast_address: 1.2.3.4
# When using multiple physical network interfaces, set this
# to true to listen on broadcast_address in addition to
# the listen_address, allowing nodes to communicate in both
# interfaces.
# Ignore this property if the network configuration automatically
# routes between the public and private networks such as EC2.
listen_on_broadcast_address: true
# Internode authentication backend, implementing IInternodeAuthenticator;
# used to allow/disallow connections from peer nodes.
# internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
# Whether to start the native transport server.
# Please note that the address on which the native transport is bound is the
# same as the rpc_address. The port however is different and specified below.
start_native_transport: true
# port for the CQL native transport to listen for clients on
# For security reasons, you should not expose this port to the internet. Firewall it if needed.
native_transport_port: 9042
# Enabling native transport encryption in client_encryption_options allows you to either use
# encryption for the standard port or to use a dedicated, additional port along with the unencrypted
# standard native_transport_port.
# Enabling client encryption and keeping native_transport_port_ssl disabled will use encryption
# for native_transport_port. Setting native_transport_port_ssl to a different value
# from native_transport_port will use encryption for native_transport_port_ssl while
# keeping native_transport_port unencrypted.
# native_transport_port_ssl: 9142
# The maximum threads for handling requests when the native transport is used.
# This is similar to rpc_max_threads though the default differs slightly (and
# there is no native_transport_min_threads, idle threads will always be stopped
# after 30 seconds).
# native_transport_max_threads: 128
#
# The maximum size of allowed frame. Frame (requests) larger than this will
# be rejected as invalid. The default is 256MB. If you’re changing this parameter,
# you may want to adjust max_value_size_in_mb accordingly.
# native_transport_max_frame_size_in_mb: 256
# The maximum number of concurrent client connections.
# The default is -1, which means unlimited.
# native_transport_max_concurrent_connections: -1
# The maximum number of concurrent client connections per source ip.
# The default is -1, which means unlimited.
# native_transport_max_concurrent_connections_per_ip: -1
# Whether to start the thrift rpc server.
start_rpc: false
# The address or interface to bind the Thrift RPC service and native transport
# server to.
#
# Set rpc_address OR rpc_interface, not both. Interfaces must correspond
# to a single address, IP aliasing is not supported.
#
# Leaving rpc_address blank has the same effect as on listen_address
# (i.e. it will be based on the configured hostname of the node).
#
# Note that unlike listen_address, you can specify 0.0.0.0, but you must also
# set broadcast_rpc_address to a value other than 0.0.0.0.
#
# For security reasons, you should not expose this port to the internet. Firewall it if needed.
#
# If you choose to specify the interface by name and the interface has an ipv4 and an ipv6 address
# you can specify which should be chosen using rpc_interface_prefer_ipv6. If false the first ipv4
# address will be used. If true the first ipv6 address will be used. Defaults to false preferring
# ipv4. If there is only one address it will be selected regardless of ipv4/ipv6.
rpc_address: 0.0.0.0
# rpc_interface: eth1
# rpc_interface_prefer_ipv6: false
# port for Thrift to listen for clients on
rpc_port: 9160
# RPC address to broadcast to drivers and other Cassandra nodes. This cannot
# be set to 0.0.0.0. If left blank, this will be set to the value of
# rpc_address. If rpc_address is set to 0.0.0.0, broadcast_rpc_address must
# be set.
broadcast_rpc_address: 10.222.33.2
# enable or disable keepalive on rpc/native connections
rpc_keepalive: true
# Cassandra provides two out-of-the-box options for the RPC Server:
#
# sync -> One thread per thrift connection. For a very large number of clients, memory
# will be your limiting factor. On a 64 bit JVM, 180KB is the minimum stack size
# per thread, and that will correspond to your use of virtual memory (but physical memory
# may be limited depending on use of stack space).
#
# hsha -> Stands for “half synchronous, half asynchronous.” All thrift clients are handled
# asynchronously using a small number of threads that does not vary with the amount
# of thrift clients (and thus scales well to many clients). The rpc requests are still
# synchronous (one thread per active request). If hsha is selected then it is essential
# that rpc_max_threads is changed from the default value of unlimited.
#
# The default is sync because on Windows hsha is about 30% slower. On Linux,
# sync/hsha performance is about the same, with hsha of course using less memory.
#
# Alternatively, can provide your own RPC server by providing the fully-qualified class name
# of an o.a.c.t.TServerFactory that can create an instance of it.
rpc_server_type: sync
# Uncomment rpc_min|max_thread to set request pool size limits.
#
# Regardless of your choice of RPC server (see above), the number of maximum requests in the
# RPC thread pool dictates how many concurrent requests are possible (but if you are using the sync
# RPC server, it also dictates the number of clients that can be connected at all).
#
# The default is unlimited and thus provides no protection against clients overwhelming the server. You are
# encouraged to set a maximum that makes sense for you in production, but do keep in mind that
# rpc_max_threads represents the maximum number of client requests this server may execute concurrently.
#
# rpc_min_threads: 16
# rpc_max_threads: 2048
# uncomment to set socket buffer sizes on rpc connections
# rpc_send_buff_size_in_bytes:
# rpc_recv_buff_size_in_bytes:
# Uncomment to set socket buffer size for internode communication
# Note that when setting this, the buffer size is limited by net.core.wmem_max
# and when not setting it it is defined by net.ipv4.tcp_wmem
# See:
# /proc/sys/net/core/wmem_max
# /proc/sys/net/core/rmem_max
# /proc/sys/net/ipv4/tcp_wmem
# /proc/sys/net/ipv4/tcp_wmem
# and: man tcp
# internode_send_buff_size_in_bytes:
# internode_recv_buff_size_in_bytes:
# Frame size for thrift (maximum message length).
thrift_framed_transport_size_in_mb: 15
# Set to true to have Cassandra create a hard link to each sstable
# flushed or streamed locally in a backups/ subdirectory of the
# keyspace data. Removing these links is the operator’s
# responsibility.
incremental_backups: false
# Whether or not to take a snapshot before each compaction. Be
# careful using this option, since Cassandra won’t clean up the
# snapshots for you. Mostly useful if you’re paranoid when there
# is a data format change.
snapshot_before_compaction: false
# Whether or not a snapshot is taken of the data before keyspace truncation
# or dropping of column families. The STRONGLY advised default of true
# should be used to provide data safety. If you set this flag to false, you will
# lose data on truncation or drop.
auto_snapshot: true
# Granularity of the collation index of rows within a partition.
# Increase if your rows are large, or if you have a very large
# number of rows per partition. The competing goals are these:
# 1) a smaller granularity means more index entries are generated
# and looking up rows withing the partition by collation column
# is faster
# 2) but, Cassandra will keep the collation index in memory for hot
# rows (as part of the key cache), so a larger granularity means
# you can cache more hot rows
column_index_size_in_kb: 64
# Per sstable indexed key cache entries (the collation index in memory
# mentioned above) exceeding this size will not be held on heap.
# This means that only partition information is held on heap and the
# index entries are read from disk.
#
# Note that this size refers to the size of the
# serialized index information and not the size of the partition.
column_index_cache_size_in_kb: 2
# Number of simultaneous compactions to allow, NOT including
# validation “compactions” for anti-entropy repair. Simultaneous
# compactions can help preserve read performance in a mixed read/write
# workload, by mitigating the tendency of small sstables to accumulate
# during a single long running compactions. The default is usually
# fine and if you experience problems with compaction running too
# slowly or too fast, you should look at
# compaction_throughput_mb_per_sec first.
#
# concurrent_compactors defaults to the smaller of (number of disks,
# number of cores), with a minimum of 2 and a maximum of 8.
#
# If your data directories are backed by SSD, you should increase this
# to the number of cores.
#concurrent_compactors: 1
# Throttles compaction to the given total throughput across the entire
# system. The faster you insert data, the faster you need to compact in
# order to keep the sstable count down, but in general, setting this to
# 16 to 32 times the rate you are inserting data is more than sufficient.
# Setting this to 0 disables throttling. Note that this account for all types
# of compaction, including validation compaction.
compaction_throughput_mb_per_sec: 16
# When compacting, the replacement sstable(s) can be opened before they
# are completely written, and used in place of the prior sstables for
# any range that has been written. This helps to smoothly transfer reads
# between the sstables, reducing page cache churn and keeping hot rows hot
sstable_preemptive_open_interval_in_mb: 50
# Throttles all outbound streaming file transfers on this node to the
# given total throughput in Mbps. This is necessary because Cassandra does
# mostly sequential IO when streaming data during bootstrap or repair, which
# can lead to saturating the network connection and degrading rpc performance.
# When unset, the default is 200 Mbps or 25 MB/s.
# stream_throughput_outbound_megabits_per_sec: 200
# Throttles all streaming file transfer between the datacenters,
# this setting allows users to throttle inter dc stream throughput in addition
# to throttling all network stream traffic as configured with
# stream_throughput_outbound_megabits_per_sec
# When unset, the default is 200 Mbps or 25 MB/s
# inter_dc_stream_throughput_outbound_megabits_per_sec: 200
# How long the coordinator should wait for read operations to complete
read_request_timeout_in_ms: 300000
# How long the coordinator should wait for seq or index scans to complete
range_request_timeout_in_ms: 300000
# How long the coordinator should wait for writes to complete
write_request_timeout_in_ms: 300000
# How long the coordinator should wait for counter writes to complete
counter_write_request_timeout_in_ms: 300000
# How long a coordinator should continue to retry a CAS operation
# that contends with other proposals for the same row
cas_contention_timeout_in_ms: 300000
# How long the coordinator should wait for truncates to complete
# (This can be much longer, because unless auto_snapshot is disabled
# we need to flush first so we can snapshot before removing the data.)
truncate_request_timeout_in_ms: 300000
# The default timeout for other, miscellaneous operations
request_timeout_in_ms: 300000
# Enable operation timeout information exchange between nodes to accurately
# measure request timeouts. If disabled, replicas will assume that requests
# were forwarded to them instantly by the coordinator, which means that
# under overload conditions we will waste that much extra time processing
# already-timed-out requests.
#
# Warning: before enabling this property make sure to ntp is installed
# and the times are synchronized between the nodes.
cross_node_timeout: false
# Set socket timeout for streaming operation.
# The stream session is failed if no data/ack is received by any of the participants
# within that period, which means this should also be sufficient to stream a large
# sstable or rebuild table indexes.
# Default value is 86400000ms, which means stale streams timeout after 24 hours.
# A value of zero means stream sockets should never time out.
# streaming_socket_timeout_in_ms: 86400000
# phi value that must be reached for a host to be marked down.
# most users should never need to adjust this.
phi_convict_threshold: 12
# endpoint_snitch — Set this to a class that implements
# IEndpointSnitch. The snitch has two functions:
# – it teaches Cassandra enough about your network topology to route
# requests efficiently
# – it allows Cassandra to spread replicas around your cluster to avoid
# correlated failures. It does this by grouping machines into
# “datacenters” and “racks.” Cassandra will do its best not to have
# more than one replica on the same “rack” (which may not actually
# be a physical location)
#
# IF YOU CHANGE THE SNITCH AFTER DATA IS INSERTED INTO THE CLUSTER,
# YOU MUST RUN A FULL REPAIR, SINCE THE SNITCH AFFECTS WHERE REPLICAS
# ARE PLACED.
#
# IF THE RACK A REPLICA IS PLACED IN CHANGES AFTER THE REPLICA HAS BEEN
# ADDED TO A RING, THE NODE MUST BE DECOMMISSIONED AND REBOOTSTRAPPED.
#
# Out of the box, Cassandra provides
# – SimpleSnitch:
# Treats Strategy order as proximity. This can improve cache
# locality when disabling read repair. Only appropriate for
# single-datacenter deployments.
# – GossipingPropertyFileSnitch
# This should be your go-to snitch for production use. The rack
# and datacenter for the local node are defined in
# cassandra-rackdc.properties and propagated to other nodes via
# gossip. If cassandra-topology.properties exists, it is used as a
# fallback, allowing migration from the PropertyFileSnitch.
# – PropertyFileSnitch:
# Proximity is determined by rack and data center, which are
# explicitly configured in cassandra-topology.properties.
# – Ec2Snitch:
# Appropriate for EC2 deployments in a single Region. Loads Region
# and Availability Zone information from the EC2 API. The Region is
# treated as the datacenter, and the Availability Zone as the rack.
# Only private IPs are used, so this will not work across multiple
# Regions.
# – Ec2MultiRegionSnitch:
# Uses public IPs as broadcast_address to allow cross-region
# connectivity. (Thus, you should set seed addresses to the public
# IP as well.) You will need to open the storage_port or
# ssl_storage_port on the public IP firewall. (For intra-Region
# traffic, Cassandra will switch to the private IP after
# establishing a connection.)
# – RackInferringSnitch:
# Proximity is determined by rack and data center, which are
# assumed to correspond to the 3rd and 2nd octet of each node’s IP
# address, respectively. Unless this happens to match your
# deployment conventions, this is best used as an example of
# writing a custom Snitch class and is provided in that spirit.
#
# You can use a custom Snitch by setting this to the full class name
# of the snitch, which will be assumed to be on your classpath.
endpoint_snitch: SimpleSnitch
# controls how often to perform the more expensive part of host score
# calculation
dynamic_snitch_update_interval_in_ms: 100
# controls how often to reset all host scores, allowing a bad host to
# possibly recover
dynamic_snitch_reset_interval_in_ms: 600000
# if set greater than zero and read_repair_chance is < 1.0, this will allow
# ‘pinning’ of replicas to hosts in order to increase cache capacity.
# The badness threshold will control how much worse the pinned host has to be
# before the dynamic snitch will prefer other replicas over it. This is
# expressed as a double which represents a percentage. Thus, a value of
# 0.2 means Cassandra would continue to prefer the static snitch values
# until the pinned host was 20% worse than the fastest.
dynamic_snitch_badness_threshold: 0.1
# request_scheduler — Set this to a class that implements
# RequestScheduler, which will schedule incoming client requests
# according to the specific policy. This is useful for multi-tenancy
# with a single Cassandra cluster.
# NOTE: This is specifically for requests from the client and does
# not affect inter node communication.
# org.apache.cassandra.scheduler.NoScheduler – No scheduling takes place
# org.apache.cassandra.scheduler.RoundRobinScheduler – Round robin of
# client requests to a node with a separate queue for each
# request_scheduler_id. The scheduler is further customized by
# request_scheduler_options as described below.
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
# Scheduler Options vary based on the type of scheduler
# NoScheduler – Has no options
# RoundRobin
# – throttle_limit — The throttle_limit is the number of in-flight
# requests per client. Requests beyond
# that limit are queued up until
# running requests can complete.
# The value of 80 here is twice the number of
# concurrent_reads + concurrent_writes.
# – default_weight — default_weight is optional and allows for
# overriding the default which is 1.
# – weights — Weights are optional and will default to 1 or the
# overridden default_weight. The weight translates into how
# many requests are handled during each turn of the
# RoundRobin, based on the scheduler id.
#
# request_scheduler_options:
# throttle_limit: 80
# default_weight: 5
# weights:
# Keyspace1: 1
# Keyspace2: 5
# request_scheduler_id — An identifier based on which to perform
# the request scheduling. Currently the only valid option is keyspace.
# request_scheduler_id: keyspace
# Enable or disable inter-node encryption
# JVM defaults for supported SSL socket protocols and cipher suites can
# be replaced using custom encryption options. This is not recommended
# unless you have policies in place that dictate certain settings, or
# need to disable vulnerable ciphers or protocols in case the JVM cannot
# be updated.
# FIPS compliant settings can be configured at JVM level and should not
# involve changing encryption settings here:
# https://docs.oracle.com/javase/8/docs/technotes/guides/security/jsse/FIPS.html
# NOTE: No custom encryption options are enabled at the moment
# The available internode options are : all, none, dc, rack
#
# If set to dc cassandra will encrypt the traffic between the DCs
# If set to rack cassandra will encrypt the traffic between the racks
#
# The passwords used in these options must match the passwords used when generating
# the keystore and truststore. For instructions on generating these files, see:
# http://download.oracle.com/javase/6/docs/technotes/guides/security/jsse/JSSERefGuide.html#CreateKeystore
#
server_encryption_options:
internode_encryption: none
keystore: conf/.keystore
keystore_password: cassandra
truststore: conf/.truststore
truststore_password: cassandra
# More advanced defaults below:
# protocol: TLS
# algorithm: SunX509
# store_type: JKS
# cipher_suites: [TLS_RSA_WITH_AES_128_CBC_SHA,TLS_RSA_WITH_AES_256_CBC_SHA,TLS_DHE_RSA_WITH_AES_128_CBC_SHA,TLS_DHE_RSA_WITH_AES_256_CBC_SHA,TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA,TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA]
# require_client_auth: false
# require_endpoint_verification: false
# enable or disable client/server encryption.
client_encryption_options:
enabled: false
# If enabled and optional is set to true encrypted and unencrypted connections are handled.
optional: false
keystore: conf/.keystore
keystore_password: cassandra
# require_client_auth: false
# Set trustore and truststore_password if require_client_auth is true
# truststore: conf/.truststore
# truststore_password: cassandra
# More advanced defaults below:
# protocol: TLS
# algorithm: SunX509
# store_type: JKS
# cipher_suites: [TLS_RSA_WITH_AES_128_CBC_SHA,TLS_RSA_WITH_AES_256_CBC_SHA,TLS_DHE_RSA_WITH_AES_128_CBC_SHA,TLS_DHE_RSA_WITH_AES_256_CBC_SHA,TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA,TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA]
# internode_compression controls whether traffic between nodes is
# compressed.
# can be: all – all traffic is compressed
# dc – traffic between different datacenters is compressed
# none – nothing is compressed.
internode_compression: all
# Enable or disable tcp_nodelay for inter-dc communication.
# Disabling it will result in larger (but fewer) network packets being sent,
# reducing overhead from the TCP protocol itself, at the cost of increasing
# latency if you block for cross-datacenter responses.
inter_dc_tcp_nodelay: false
# TTL for different trace types used during logging of the repair process.
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
# UDFs (user defined functions) are disabled by default.
# As of Cassandra 3.0 there is a sandbox in place that should prevent execution of evil code.
enable_user_defined_functions: false
# Enables scripted UDFs (JavaScript UDFs).
# Java UDFs are always enabled, if enable_user_defined_functions is true.
# Enable this option to be able to use UDFs with “language javascript” or any custom JSR-223 provider.
# This option has no effect, if enable_user_defined_functions is false.
enable_scripted_user_defined_functions: false
# The default Windows kernel timer and scheduling resolution is 15.6ms for power conservation.
# Lowering this value on Windows can provide much tighter latency and better throughput, however
# some virtualized environments may see a negative performance impact from changing this setting
# below their system default. The sysinternals ‘clockres’ tool can confirm your system’s default
# setting.
windows_timer_interval: 16
# Enables encrypting data at-rest (on disk). Different key providers can be plugged in, but the default reads from
# a JCE-style keystore. A single keystore can hold multiple keys, but the one referenced by
# the “key_alias” is the only key that will be used for encrypt opertaions; previously used keys
# can still (and should!) be in the keystore and will be used on decrypt operations
# (to handle the case of key rotation).
#
# It is strongly recommended to download and install Java Cryptography Extension (JCE)
# Unlimited Strength Jurisdiction Policy Files for your version of the JDK.
# (current link: http://www.oracle.com/technetwork/java/javase/downloads/jce8-download-2133166.html)
#
# Currently, only the following file types are supported for transparent data encryption, although
# more are coming in future cassandra releases: commitlog, hints
transparent_data_encryption_options:
enabled: false
chunk_length_kb: 64
cipher: AES/CBC/PKCS5Padding
key_alias: testing:1
# CBC IV length for AES needs to be 16 bytes (which is also the default size)
# iv_length: 16
key_provider:
– class_name: org.apache.cassandra.security.JKSKeyProvider
parameters:
– keystore: conf/.keystore
keystore_password: cassandra
store_type: JCEKS
key_password: cassandra
#####################
# SAFETY THRESHOLDS #
#####################
# When executing a scan, within or across a partition, we need to keep the
# tombstones seen in memory so we can return them to the coordinator, which
# will use them to make sure other replicas also know about the deleted rows.
# With workloads that generate a lot of tombstones, this can cause performance
# problems and even exaust the server heap.
# (http://www.datastax.com/dev/blog/cassandra-anti-patterns-queues-and-queue-like-datasets)
# Adjust the thresholds here if you understand the dangers and want to
# scan more tombstones anyway. These thresholds may also be adjusted at runtime
# using the StorageService mbean.
tombstone_warn_threshold: 10000
tombstone_failure_threshold: 1000000
# Log WARN on any batch size exceeding this value. 5kb per batch by default.
# Caution should be taken on increasing the size of this threshold as it can lead to node instability.
batch_size_warn_threshold_in_kb: 5
# Fail any batch exceeding this value. 50kb (10x warn threshold) by default.
batch_size_fail_threshold_in_kb: 50
# Log WARN on any batches not of type LOGGED than span across more partitions than this limit
unlogged_batch_across_partitions_warn_threshold: 10
# Log a warning when compacting partitions larger than this value
compaction_large_partition_warning_threshold_mb: 100
# GC Pauses greater than gc_warn_threshold_in_ms will be logged at WARN level
# Adjust the threshold based on your application throughput requirement
# By default, Cassandra logs GC Pauses greater than 200 ms at INFO level
gc_warn_threshold_in_ms: 1000
# Maximum size of any value in SSTables. Safety measure to detect SSTable corruption
# early. Any value size larger than this threshold will result into marking an SSTable
# as corrupted.
# max_value_size_in_mb: 256
Online agent:
# Cassandra storage config YAML
# NOTE:
# See http://wiki.apache.org/cassandra/StorageConfiguration for
# full explanations of configuration directives
# /NOTE
# The name of the cluster. This is mainly used to prevent machines in
# one logical cluster from joining another.
cluster_name: ‘DMS’
# This defines the number of tokens randomly assigned to this node on the ring
# The more tokens, relative to other nodes, the larger the proportion of data
# that this node will store. You probably want all nodes to have the same number
# of tokens assuming they have equal hardware capability.
#
# If you leave this unspecified, Cassandra will use the default of 1 token for legacy compatibility,
# and will use the initial_token as described below.
#
# Specifying initial_token will override this setting on the node’s initial start,
# on subsequent starts, this setting will apply even if initial token is set.
#
# If you already have a cluster with 1 token per node, and wish to migrate to
# multiple tokens per node, see http://wiki.apache.org/cassandra/Operations
num_tokens: 256
# Triggers automatic allocation of num_tokens tokens for this node. The allocation
# algorithm attempts to choose tokens in a way that optimizes replicated load over
# the nodes in the datacenter for the replication strategy used by the specified
# keyspace.
#
# The load assigned to each node will be close to proportional to its number of
# vnodes.
#
# Only supported with the Murmur3Partitioner.
# allocate_tokens_for_keyspace: KEYSPACE
# initial_token allows you to specify tokens manually. While you can use # it with
# vnodes (num_tokens > 1, above) — in which case you should provide a
# comma-separated list — it’s primarily used when adding nodes # to legacy clusters
# that do not have vnodes enabled.
# initial_token:
# See http://wiki.apache.org/cassandra/HintedHandoff
# May either be “true” or “false” to enable globally
hinted_handoff_enabled: true
# When hinted_handoff_enabled is true, a black list of data centers that will not
# perform hinted handoff
#hinted_handoff_disabled_datacenters:
# – DC1
# – DC2
# this defines the maximum amount of time a dead host will have hints
# generated. After it has been dead this long, new hints for it will not be
# created until it has been seen alive and gone down again.
max_hint_window_in_ms: 10800000 # 3 hours
# Maximum throttle in KBs per second, per delivery thread. This will be
# reduced proportionally to the number of nodes in the cluster. (If there
# are two nodes in the cluster, each delivery thread will use the maximum
# rate; if there are three, each will throttle to half of the maximum,
# since we expect two nodes to be delivering hints simultaneously.)
hinted_handoff_throttle_in_kb: 1024
# Number of threads with which to deliver hints;
# Consider increasing this number when you have multi-dc deployments, since
# cross-dc handoff tends to be slower
max_hints_delivery_threads: 2
# Directory where Cassandra should store hints.
# If not set, the default directory is $CASSANDRA_HOME/data/hints.
# hints_directory: /var/lib/cassandra/hints
# How often hints should be flushed from the internal buffers to disk.
# Will *not* trigger fsync.
hints_flush_period_in_ms: 10000
# Maximum size for a single hints file, in megabytes.
max_hints_file_size_in_mb: 128
# Compression to apply to the hint files. If omitted, hints files
# will be written uncompressed. LZ4, Snappy, and Deflate compressors
# are supported.
#hints_compression:
# – class_name: LZ4Compressor
# parameters:
# –
# Maximum throttle in KBs per second, total. This will be
# reduced proportionally to the number of nodes in the cluster.
batchlog_replay_throttle_in_kb: 1024
# Authentication backend, implementing IAuthenticator; used to identify users
# Out of the box, Cassandra provides org.apache.cassandra.auth.{AllowAllAuthenticator,
# PasswordAuthenticator}.
#
# – AllowAllAuthenticator performs no checks – set it to disable authentication.
# – PasswordAuthenticator relies on username/password pairs to authenticate
# users. It keeps usernames and hashed passwords in system_auth.credentials table.
# Please increase system_auth keyspace replication factor if you use this authenticator.
# If using PasswordAuthenticator, CassandraRoleManager must also be used (see below)
authenticator: PasswordAuthenticator
# Authorization backend, implementing IAuthorizer; used to limit access/provide permissions
# Out of the box, Cassandra provides org.apache.cassandra.auth.{AllowAllAuthorizer,
# CassandraAuthorizer}.
#
# – AllowAllAuthorizer allows any action to any user – set it to disable authorization.
# – CassandraAuthorizer stores permissions in system_auth.permissions table. Please
# increase system_auth keyspace replication factor if you use this authorizer.
authorizer: AllowAllAuthorizer
# Part of the Authentication & Authorization backend, implementing IRoleManager; used
# to maintain grants and memberships between roles.
# Out of the box, Cassandra provides org.apache.cassandra.auth.CassandraRoleManager,
# which stores role information in the system_auth keyspace. Most functions of the
# IRoleManager require an authenticated login, so unless the configured IAuthenticator
# actually implements authentication, most of this functionality will be unavailable.
#
# – CassandraRoleManager stores role data in the system_auth keyspace. Please
# increase system_auth keyspace replication factor if you use this role manager.
role_manager: CassandraRoleManager
# Validity period for roles cache (fetching granted roles can be an expensive
# operation depending on the role manager, CassandraRoleManager is one example)
# Granted roles are cached for authenticated sessions in AuthenticatedUser and
# after the period specified here, become eligible for (async) reload.
# Defaults to 2000, set to 0 to disable caching entirely.
# Will be disabled automatically for AllowAllAuthenticator.
roles_validity_in_ms: 2000
# Refresh interval for roles cache (if enabled).
# After this interval, cache entries become eligible for refresh. Upon next
# access, an async reload is scheduled and the old value returned until it
# completes. If roles_validity_in_ms is non-zero, then this must be
# also.
# Defaults to the same value as roles_validity_in_ms.
# roles_update_interval_in_ms: 2000
# Validity period for permissions cache (fetching permissions can be an
# expensive operation depending on the authorizer, CassandraAuthorizer is
# one example). Defaults to 2000, set to 0 to disable.
# Will be disabled automatically for AllowAllAuthorizer.
permissions_validity_in_ms: 2000
# Refresh interval for permissions cache (if enabled).
# After this interval, cache entries become eligible for refresh. Upon next
# access, an async reload is scheduled and the old value returned until it
# completes. If permissions_validity_in_ms is non-zero, then this must be
# also.
# Defaults to the same value as permissions_validity_in_ms.
# permissions_update_interval_in_ms: 2000
# Validity period for credentials cache. This cache is tightly coupled to
# the provided PasswordAuthenticator implementation of IAuthenticator. If
# another IAuthenticator implementation is configured, this cache will not
# be automatically used and so the following settings will have no effect.
# Please note, credentials are cached in their encrypted form, so while
# activating this cache may reduce the number of queries made to the
# underlying table, it may not bring a significant reduction in the
# latency of individual authentication attempts.
# Defaults to 2000, set to 0 to disable credentials caching.
credentials_validity_in_ms: 2000
# Refresh interval for credentials cache (if enabled).
# After this interval, cache entries become eligible for refresh. Upon next
# access, an async reload is scheduled and the old value returned until it
# completes. If credentials_validity_in_ms is non-zero, then this must be
# also.
# Defaults to the same value as credentials_validity_in_ms.
# credentials_update_interval_in_ms: 2000
# The partitioner is responsible for distributing groups of rows (by
# partition key) across nodes in the cluster. You should leave this
# alone for new clusters. The partitioner can NOT be changed without
# reloading all data, so when upgrading you should set this to the
# same partitioner you were already using.
#
# Besides Murmur3Partitioner, partitioners included for backwards
# compatibility include RandomPartitioner, ByteOrderedPartitioner, and
# OrderPreservingPartitioner.
#
partitioner: org.apache.cassandra.dht.Murmur3Partitioner
# Directories where Cassandra should store data on disk. Cassandra
# will spread data evenly across them, subject to the granularity of
# the configured compaction strategy.
# If not set, the default directory is $CASSANDRA_HOME/data/data.
data_file_directories:
– E:\ProgramData\Cassandra
# commit log. when running on magnetic HDD, this should be a
# separate spindle than the data directories.
# If not set, the default directory is $CASSANDRA_HOME/data/commitlog.
# commitlog_directory: /var/lib/cassandra/commitlog
# policy for data disk failures:
# die: shut down gossip and client transports and kill the JVM for any fs errors or
# single-sstable errors, so the node can be replaced.
# stop_paranoid: shut down gossip and client transports even for single-sstable errors,
# kill the JVM for errors during startup.
# stop: shut down gossip and client transports, leaving the node effectively dead, but
# can still be inspected via JMX, kill the JVM for errors during startup.
# best_effort: stop using the failed disk and respond to requests based on
# remaining available sstables. This means you WILL see obsolete
# data at CL.ONE!
# ignore: ignore fatal errors and let requests fail, as in pre-1.2 Cassandra
disk_failure_policy: stop
# policy for commit disk failures:
# die: shut down gossip and Thrift and kill the JVM, so the node can be replaced.
# stop: shut down gossip and Thrift, leaving the node effectively dead, but
# can still be inspected via JMX.
# stop_commit: shutdown the commit log, letting writes collect but
# continuing to service reads, as in pre-2.0.5 Cassandra
# ignore: ignore fatal errors and let the batches fail
commit_failure_policy: stop
# Maximum size of the native protocol prepared statement cache
#
# Valid values are either “auto” (omitting the value) or a value greater 0.
#
# Note that specifying a too large value will result in long running GCs and possbily
# out-of-memory errors. Keep the value at a small fraction of the heap.
#
# If you constantly see “prepared statements discarded in the last minute because
# cache limit reached” messages, the first step is to investigate the root cause
# of these messages and check whether prepared statements are used correctly –
# i.e. use bind markers for variable parts.
#
# Do only change the default value, if you really have more prepared statements than
# fit in the cache. In most cases it is not neccessary to change this value.
# Constantly re-preparing statements is a performance penalty.
#
# Default value (“auto”) is 1/256th of the heap or 10MB, whichever is greater
prepared_statements_cache_size_mb:
# Maximum size of the Thrift prepared statement cache
#
# If you do not use Thrift at all, it is safe to leave this value at “auto”.
#
# See description of ‘prepared_statements_cache_size_mb’ above for more information.
#
# Default value (“auto”) is 1/256th of the heap or 10MB, whichever is greater
thrift_prepared_statements_cache_size_mb:
# Maximum size of the key cache in memory.
#
# Each key cache hit saves 1 seek and each row cache hit saves 2 seeks at the
# minimum, sometimes more. The key cache is fairly tiny for the amount of
# time it saves, so it’s worthwhile to use it at large numbers.
# The row cache saves even more time, but must contain the entire row,
# so it is extremely space-intensive. It’s best to only use the
# row cache if you have hot rows or static rows.
#
# NOTE: if you reduce the size, you may not get you hottest keys loaded on startup.
#
# Default value is empty to make it “auto” (min(5% of Heap (in MB), 100MB)). Set to 0 to disable key cache.
key_cache_size_in_mb:
# Duration in seconds after which Cassandra should
# save the key cache. Caches are saved to saved_caches_directory as
# specified in this configuration file.
#
# Saved caches greatly improve cold-start speeds, and is relatively cheap in
# terms of I/O for the key cache. Row cache saving is much more expensive and
# has limited use.
#
# Default is 14400 or 4 hours.
key_cache_save_period: 14400
# Number of keys from the key cache to save
# Disabled by default, meaning all keys are going to be saved
# key_cache_keys_to_save: 100
# Row cache implementation class name.
# Available implementations:
# org.apache.cassandra.cache.OHCProvider Fully off-heap row cache implementation (default).
# org.apache.cassandra.cache.SerializingCacheProvider This is the row cache implementation availabile
# in previous releases of Cassandra.
# row_cache_class_name: org.apache.cassandra.cache.OHCProvider
# Maximum size of the row cache in memory.
# Please note that OHC cache implementation requires some additional off-heap memory to manage
# the map structures and some in-flight memory during operations before/after cache entries can be
# accounted against the cache capacity. This overhead is usually small compared to the whole capacity.
# Do not specify more memory that the system can afford in the worst usual situation and leave some
# headroom for OS block level cache. Do never allow your system to swap.
#
# Default value is 0, to disable row caching.
row_cache_size_in_mb: 0
# Duration in seconds after which Cassandra should save the row cache.
# Caches are saved to saved_caches_directory as specified in this configuration file.
#
# Saved caches greatly improve cold-start speeds, and is relatively cheap in
# terms of I/O for the key cache. Row cache saving is much more expensive and
# has limited use.
#
# Default is 0 to disable saving the row cache.
row_cache_save_period: 0
# Number of keys from the row cache to save.
# Specify 0 (which is the default), meaning all keys are going to be saved
# row_cache_keys_to_save: 100
# Maximum size of the counter cache in memory.
#
# Counter cache helps to reduce counter locks’ contention for hot counter cells.
# In case of RF = 1 a counter cache hit will cause Cassandra to skip the read before
# write entirely. With RF > 1 a counter cache hit will still help to reduce the duration
# of the lock hold, helping with hot counter cell updates, but will not allow skipping
# the read entirely. Only the local (clock, count) tuple of a counter cell is kept
# in memory, not the whole counter, so it’s relatively cheap.
#
# NOTE: if you reduce the size, you may not get you hottest keys loaded on startup.
#
# Default value is empty to make it “auto” (min(2.5% of Heap (in MB), 50MB)). Set to 0 to disable counter cache.
# NOTE: if you perform counter deletes and rely on low gcgs, you should disable the counter cache.
counter_cache_size_in_mb:
# Duration in seconds after which Cassandra should
# save the counter cache (keys only). Caches are saved to saved_caches_directory as
# specified in this configuration file.
#
# Default is 7200 or 2 hours.
counter_cache_save_period: 7200
# Number of keys from the counter cache to save
# Disabled by default, meaning all keys are going to be saved
# counter_cache_keys_to_save: 100
# saved caches
# If not set, the default directory is $CASSANDRA_HOME/data/saved_caches.
# saved_caches_directory: /var/lib/cassandra/saved_caches
# commitlog_sync may be either “periodic” or “batch.”
#
# When in batch mode, Cassandra won’t ack writes until the commit log
# has been fsynced to disk. It will wait
# commitlog_sync_batch_window_in_ms milliseconds between fsyncs.
# This window should be kept short because the writer threads will
# be unable to do extra work while waiting. (You may need to increase
# concurrent_writes for the same reason.)
#
# commitlog_sync: batch
# commitlog_sync_batch_window_in_ms: 2
#
# the other option is “periodic” where writes may be acked immediately
# and the CommitLog is simply synced every commitlog_sync_period_in_ms
# milliseconds.
commitlog_sync: periodic
commitlog_sync_period_in_ms: 10000
# The size of the individual commitlog file segments. A commitlog
# segment may be archived, deleted, or recycled once all the data
# in it (potentially from each columnfamily in the system) has been
# flushed to sstables.
#
# The default size is 32, which is almost always fine, but if you are
# archiving commitlog segments (see commitlog_archiving.properties),
# then you probably want a finer granularity of archiving; 8 or 16 MB
# is reasonable.
# Max mutation size is also configurable via max_mutation_size_in_kb setting in
# cassandra.yaml. The default is half the size commitlog_segment_size_in_mb * 1024.
#
# NOTE: If max_mutation_size_in_kb is set explicitly then commitlog_segment_size_in_mb must
# be set to at least twice the size of max_mutation_size_in_kb / 1024
#
commitlog_segment_size_in_mb: 32
# Compression to apply to the commit log. If omitted, the commit log
# will be written uncompressed. LZ4, Snappy, and Deflate compressors
# are supported.
#commitlog_compression:
# – class_name: LZ4Compressor
# parameters:
# –
# any class that implements the SeedProvider interface and has a
# constructor that takes a Map<String, String> of parameters will do.
seed_provider:
# Addresses of hosts that are deemed contact points.
# Cassandra nodes use this list of hosts to find each other and learn
# the topology of the ring. You must change this if you are running
# multiple nodes!
– class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
# seeds is actually a comma-delimited list of addresses.
# Ex: “<ip1>,<ip2>,<ip3>”
– seeds: “10.222.33.1,10.222.33.2”
# For workloads with more data than can fit in memory, Cassandra’s
# bottleneck will be reads that need to fetch data from
# disk. “concurrent_reads” should be set to (16 * number_of_drives) in
# order to allow the operations to enqueue low enough in the stack
# that the OS and drives can reorder them. Same applies to
# “concurrent_counter_writes”, since counter writes read the current
# values before incrementing and writing them back.
#
# On the other hand, since writes are almost never IO bound, the ideal
# number of “concurrent_writes” is dependent on the number of cores in
# your system; (8 * number_of_cores) is a good rule of thumb.
concurrent_reads: 32
concurrent_writes: 32
concurrent_counter_writes: 32
# For materialized view writes, as there is a read involved, so this should
# be limited by the less of concurrent reads or concurrent writes.
concurrent_materialized_view_writes: 32
# Maximum memory to use for sstable chunk cache and buffer pooling.
# 32MB of this are reserved for pooling buffers, the rest is used as an
# cache that holds uncompressed sstable chunks.
# Defaults to the smaller of 1/4 of heap or 512MB. This pool is allocated off-heap,
# so is in addition to the memory allocated for heap. The cache also has on-heap
# overhead which is roughly 128 bytes per chunk (i.e. 0.2% of the reserved size
# if the default 64k chunk size is used).
# Memory is only allocated when needed.
# file_cache_size_in_mb: 512
# Flag indicating whether to allocate on or off heap when the sstable buffer
# pool is exhausted, that is when it has exceeded the maximum memory
# file_cache_size_in_mb, beyond which it will not cache buffers but allocate on request.
# buffer_pool_use_heap_if_exhausted: true
# The strategy for optimizing disk read
# Possible values are:
# ssd (for solid state disks, the default)
# spinning (for spinning disks)
disk_optimization_strategy: spinning
# Total permitted memory to use for memtables. Cassandra will stop
# accepting writes when the limit is exceeded until a flush completes,
# and will trigger a flush based on memtable_cleanup_threshold
# If omitted, Cassandra will set both to 1/4 the size of the heap.
# memtable_heap_space_in_mb: 2048
# memtable_offheap_space_in_mb: 2048
# Ratio of occupied non-flushing memtable size to total permitted size
# that will trigger a flush of the largest memtable. Larger mct will
# mean larger flushes and hence less compaction, but also less concurrent
# flush activity which can make it difficult to keep your disks fed
# under heavy write load.
#
# memtable_cleanup_threshold defaults to 1 / (memtable_flush_writers + 1)
# memtable_cleanup_threshold: 0.11
# Specify the way Cassandra allocates and manages memtable memory.
# Options are:
# heap_buffers: on heap nio buffers
# offheap_buffers: off heap (direct) nio buffers
# offheap_objects: off heap objects
memtable_allocation_type: heap_buffers
# Total space to use for commit logs on disk.
#
# If space gets above this value, Cassandra will flush every dirty CF
# in the oldest segment and remove it. So a small total commitlog space
# will tend to cause more flush activity on less-active columnfamilies.
#
# The default value is the smaller of 8192, and 1/4 of the total space
# of the commitlog volume.
#
# commitlog_total_space_in_mb: 8192
# This sets the amount of memtable flush writer threads. These will
# be blocked by disk io, and each one will hold a memtable in memory
# while blocked.
#
# memtable_flush_writers defaults to one per data_file_directory.
#
# If your data directories are backed by SSD, you can increase this, but
# avoid having memtable_flush_writers * data_file_directories > number of cores
#memtable_flush_writers: 1
# A fixed memory pool size in MB for for SSTable index summaries. If left
# empty, this will default to 5% of the heap size. If the memory usage of
# all index summaries exceeds this limit, SSTables with low read rates will
# shrink their index summaries in order to meet this limit. However, this
# is a best-effort process. In extreme conditions Cassandra may need to use
# more than this amount of memory.
index_summary_capacity_in_mb:
# How frequently index summaries should be resampled. This is done
# periodically to redistribute memory from the fixed-size pool to sstables
# proportional their recent read rates. Setting to -1 will disable this
# process, leaving existing index summaries at their current sampling level.
index_summary_resize_interval_in_minutes: 60
# Whether to, when doing sequential writing, fsync() at intervals in
# order to force the operating system to flush the dirty
# buffers. Enable this to avoid sudden dirty buffer flushing from
# impacting read latencies. Almost always a good idea on SSDs; not
# necessarily on platters.
trickle_fsync: false
trickle_fsync_interval_in_kb: 10240
# TCP port, for commands and data
# For security reasons, you should not expose this port to the internet. Firewall it if needed.
storage_port: 7000
# SSL port, for encrypted communication. Unused unless enabled in
# encryption_options
# For security reasons, you should not expose this port to the internet. Firewall it if needed.
ssl_storage_port: 7001
# Address or interface to bind to and tell other Cassandra nodes to connect to.
# You _must_ change this if you want multiple nodes to be able to communicate!
#
# Set listen_address OR listen_interface, not both. Interfaces must correspond
# to a single address, IP aliasing is not supported.
#
# Leaving it blank leaves it up to InetAddress.getLocalHost(). This
# will always do the Right Thing _if_ the node is properly configured
# (hostname, name resolution, etc), and the Right Thing is to use the
# address associated with the hostname (it might not be).
#
# Setting listen_address to 0.0.0.0 is always wrong.
#
# If you choose to specify the interface by name and the interface has an ipv4 and an ipv6 address
# you can specify which should be chosen using listen_interface_prefer_ipv6. If false the first ipv4
# address will be used. If true the first ipv6 address will be used. Defaults to false preferring
# ipv4. If there is only one address it will be selected regardless of ipv4/ipv6.
listen_address: 10.222.33.1
# listen_interface: eth0
# listen_interface_prefer_ipv6: false
# Address to broadcast to other Cassandra nodes
# Leaving this blank will set it to the same value as listen_address
# broadcast_address: 1.2.3.4
# When using multiple physical network interfaces, set this
# to true to listen on broadcast_address in addition to
# the listen_address, allowing nodes to communicate in both
# interfaces.
# Ignore this property if the network configuration automatically
# routes between the public and private networks such as EC2.
listen_on_broadcast_address: true
# Internode authentication backend, implementing IInternodeAuthenticator;
# used to allow/disallow connections from peer nodes.
# internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
# Whether to start the native transport server.
# Please note that the address on which the native transport is bound is the
# same as the rpc_address. The port however is different and specified below.
start_native_transport: true
# port for the CQL native transport to listen for clients on
# For security reasons, you should not expose this port to the internet. Firewall it if needed.
native_transport_port: 9042
# Enabling native transport encryption in client_encryption_options allows you to either use
# encryption for the standard port or to use a dedicated, additional port along with the unencrypted
# standard native_transport_port.
# Enabling client encryption and keeping native_transport_port_ssl disabled will use encryption
# for native_transport_port. Setting native_transport_port_ssl to a different value
# from native_transport_port will use encryption for native_transport_port_ssl while
# keeping native_transport_port unencrypted.
# native_transport_port_ssl: 9142
# The maximum threads for handling requests when the native transport is used.
# This is similar to rpc_max_threads though the default differs slightly (and
# there is no native_transport_min_threads, idle threads will always be stopped
# after 30 seconds).
# native_transport_max_threads: 128
#
# The maximum size of allowed frame. Frame (requests) larger than this will
# be rejected as invalid. The default is 256MB. If you’re changing this parameter,
# you may want to adjust max_value_size_in_mb accordingly.
# native_transport_max_frame_size_in_mb: 256
# The maximum number of concurrent client connections.
# The default is -1, which means unlimited.
# native_transport_max_concurrent_connections: -1
# The maximum number of concurrent client connections per source ip.
# The default is -1, which means unlimited.
# native_transport_max_concurrent_connections_per_ip: -1
# Whether to start the thrift rpc server.
start_rpc: false
# The address or interface to bind the Thrift RPC service and native transport
# server to.
#
# Set rpc_address OR rpc_interface, not both. Interfaces must correspond
# to a single address, IP aliasing is not supported.
#
# Leaving rpc_address blank has the same effect as on listen_address
# (i.e. it will be based on the configured hostname of the node).
#
# Note that unlike listen_address, you can specify 0.0.0.0, but you must also
# set broadcast_rpc_address to a value other than 0.0.0.0.
#
# For security reasons, you should not expose this port to the internet. Firewall it if needed.
#
# If you choose to specify the interface by name and the interface has an ipv4 and an ipv6 address
# you can specify which should be chosen using rpc_interface_prefer_ipv6. If false the first ipv4
# address will be used. If true the first ipv6 address will be used. Defaults to false preferring
# ipv4. If there is only one address it will be selected regardless of ipv4/ipv6.
rpc_address: 0.0.0.0
# rpc_interface: eth1
# rpc_interface_prefer_ipv6: false
# port for Thrift to listen for clients on
rpc_port: 9160
# RPC address to broadcast to drivers and other Cassandra nodes. This cannot
# be set to 0.0.0.0. If left blank, this will be set to the value of
# rpc_address. If rpc_address is set to 0.0.0.0, broadcast_rpc_address must
# be set.
broadcast_rpc_address: 10.222.33.1
# enable or disable keepalive on rpc/native connections
rpc_keepalive: true
# Cassandra provides two out-of-the-box options for the RPC Server:
#
# sync -> One thread per thrift connection. For a very large number of clients, memory
# will be your limiting factor. On a 64 bit JVM, 180KB is the minimum stack size
# per thread, and that will correspond to your use of virtual memory (but physical memory
# may be limited depending on use of stack space).
#
# hsha -> Stands for “half synchronous, half asynchronous.” All thrift clients are handled
# asynchronously using a small number of threads that does not vary with the amount
# of thrift clients (and thus scales well to many clients). The rpc requests are still
# synchronous (one thread per active request). If hsha is selected then it is essential
# that rpc_max_threads is changed from the default value of unlimited.
#
# The default is sync because on Windows hsha is about 30% slower. On Linux,
# sync/hsha performance is about the same, with hsha of course using less memory.
#
# Alternatively, can provide your own RPC server by providing the fully-qualified class name
# of an o.a.c.t.TServerFactory that can create an instance of it.
rpc_server_type: sync
# Uncomment rpc_min|max_thread to set request pool size limits.
#
# Regardless of your choice of RPC server (see above), the number of maximum requests in the
# RPC thread pool dictates how many concurrent requests are possible (but if you are using the sync
# RPC server, it also dictates the number of clients that can be connected at all).
#
# The default is unlimited and thus provides no protection against clients overwhelming the server. You are
# encouraged to set a maximum that makes sense for you in production, but do keep in mind that
# rpc_max_threads represents the maximum number of client requests this server may execute concurrently.
#
# rpc_min_threads: 16
# rpc_max_threads: 2048
# uncomment to set socket buffer sizes on rpc connections
# rpc_send_buff_size_in_bytes:
# rpc_recv_buff_size_in_bytes:
# Uncomment to set socket buffer size for internode communication
# Note that when setting this, the buffer size is limited by net.core.wmem_max
# and when not setting it it is defined by net.ipv4.tcp_wmem
# See:
# /proc/sys/net/core/wmem_max
# /proc/sys/net/core/rmem_max
# /proc/sys/net/ipv4/tcp_wmem
# /proc/sys/net/ipv4/tcp_wmem
# and: man tcp
# internode_send_buff_size_in_bytes:
# internode_recv_buff_size_in_bytes:
# Frame size for thrift (maximum message length).
thrift_framed_transport_size_in_mb: 15
# Set to true to have Cassandra create a hard link to each sstable
# flushed or streamed locally in a backups/ subdirectory of the
# keyspace data. Removing these links is the operator’s
# responsibility.
incremental_backups: false
# Whether or not to take a snapshot before each compaction. Be
# careful using this option, since Cassandra won’t clean up the
# snapshots for you. Mostly useful if you’re paranoid when there
# is a data format change.
snapshot_before_compaction: false
# Whether or not a snapshot is taken of the data before keyspace truncation
# or dropping of column families. The STRONGLY advised default of true
# should be used to provide data safety. If you set this flag to false, you will
# lose data on truncation or drop.
auto_snapshot: true
# Granularity of the collation index of rows within a partition.
# Increase if your rows are large, or if you have a very large
# number of rows per partition. The competing goals are these:
# 1) a smaller granularity means more index entries are generated
# and looking up rows withing the partition by collation column
# is faster
# 2) but, Cassandra will keep the collation index in memory for hot
# rows (as part of the key cache), so a larger granularity means
# you can cache more hot rows
column_index_size_in_kb: 64
# Per sstable indexed key cache entries (the collation index in memory
# mentioned above) exceeding this size will not be held on heap.
# This means that only partition information is held on heap and the
# index entries are read from disk.
#
# Note that this size refers to the size of the
# serialized index information and not the size of the partition.
column_index_cache_size_in_kb: 2
# Number of simultaneous compactions to allow, NOT including
# validation “compactions” for anti-entropy repair. Simultaneous
# compactions can help preserve read performance in a mixed read/write
# workload, by mitigating the tendency of small sstables to accumulate
# during a single long running compactions. The default is usually
# fine and if you experience problems with compaction running too
# slowly or too fast, you should look at
# compaction_throughput_mb_per_sec first.
#
# concurrent_compactors defaults to the smaller of (number of disks,
# number of cores), with a minimum of 2 and a maximum of 8.
#
# If your data directories are backed by SSD, you should increase this
# to the number of cores.
#concurrent_compactors: 1
# Throttles compaction to the given total throughput across the entire
# system. The faster you insert data, the faster you need to compact in
# order to keep the sstable count down, but in general, setting this to
# 16 to 32 times the rate you are inserting data is more than sufficient.
# Setting this to 0 disables throttling. Note that this account for all types
# of compaction, including validation compaction.
compaction_throughput_mb_per_sec: 16
# When compacting, the replacement sstable(s) can be opened before they
# are completely written, and used in place of the prior sstables for
# any range that has been written. This helps to smoothly transfer reads
# between the sstables, reducing page cache churn and keeping hot rows hot
sstable_preemptive_open_interval_in_mb: 50
# Throttles all outbound streaming file transfers on this node to the
# given total throughput in Mbps. This is necessary because Cassandra does
# mostly sequential IO when streaming data during bootstrap or repair, which
# can lead to saturating the network connection and degrading rpc performance.
# When unset, the default is 200 Mbps or 25 MB/s.
# stream_throughput_outbound_megabits_per_sec: 200
# Throttles all streaming file transfer between the datacenters,
# this setting allows users to throttle inter dc stream throughput in addition
# to throttling all network stream traffic as configured with
# stream_throughput_outbound_megabits_per_sec
# When unset, the default is 200 Mbps or 25 MB/s
# inter_dc_stream_throughput_outbound_megabits_per_sec: 200
# How long the coordinator should wait for read operations to complete
read_request_timeout_in_ms: 300000
# How long the coordinator should wait for seq or index scans to complete
range_request_timeout_in_ms: 300000
# How long the coordinator should wait for writes to complete
write_request_timeout_in_ms: 300000
# How long the coordinator should wait for counter writes to complete
counter_write_request_timeout_in_ms: 300000
# How long a coordinator should continue to retry a CAS operation
# that contends with other proposals for the same row
cas_contention_timeout_in_ms: 300000
# How long the coordinator should wait for truncates to complete
# (This can be much longer, because unless auto_snapshot is disabled
# we need to flush first so we can snapshot before removing the data.)
truncate_request_timeout_in_ms: 300000
# The default timeout for other, miscellaneous operations
request_timeout_in_ms: 300000
# Enable operation timeout information exchange between nodes to accurately
# measure request timeouts. If disabled, replicas will assume that requests
# were forwarded to them instantly by the coordinator, which means that
# under overload conditions we will waste that much extra time processing
# already-timed-out requests.
#
# Warning: before enabling this property make sure to ntp is installed
# and the times are synchronized between the nodes.
cross_node_timeout: false
# Set socket timeout for streaming operation.
# The stream session is failed if no data/ack is received by any of the participants
# within that period, which means this should also be sufficient to stream a large
# sstable or rebuild table indexes.
# Default value is 86400000ms, which means stale streams timeout after 24 hours.
# A value of zero means stream sockets should never time out.
# streaming_socket_timeout_in_ms: 86400000
# phi value that must be reached for a host to be marked down.
# most users should never need to adjust this.
phi_convict_threshold: 12
# endpoint_snitch — Set this to a class that implements
# IEndpointSnitch. The snitch has two functions:
# – it teaches Cassandra enough about your network topology to route
# requests efficiently
# – it allows Cassandra to spread replicas around your cluster to avoid
# correlated failures. It does this by grouping machines into
# “datacenters” and “racks.” Cassandra will do its best not to have
# more than one replica on the same “rack” (which may not actually
# be a physical location)
#
# IF YOU CHANGE THE SNITCH AFTER DATA IS INSERTED INTO THE CLUSTER,
# YOU MUST RUN A FULL REPAIR, SINCE THE SNITCH AFFECTS WHERE REPLICAS
# ARE PLACED.
#
# IF THE RACK A REPLICA IS PLACED IN CHANGES AFTER THE REPLICA HAS BEEN
# ADDED TO A RING, THE NODE MUST BE DECOMMISSIONED AND REBOOTSTRAPPED.
#
# Out of the box, Cassandra provides
# – SimpleSnitch:
# Treats Strategy order as proximity. This can improve cache
# locality when disabling read repair. Only appropriate for
# single-datacenter deployments.
# – GossipingPropertyFileSnitch
# This should be your go-to snitch for production use. The rack
# and datacenter for the local node are defined in
# cassandra-rackdc.properties and propagated to other nodes via
# gossip. If cassandra-topology.properties exists, it is used as a
# fallback, allowing migration from the PropertyFileSnitch.
# – PropertyFileSnitch:
# Proximity is determined by rack and data center, which are
# explicitly configured in cassandra-topology.properties.
# – Ec2Snitch:
# Appropriate for EC2 deployments in a single Region. Loads Region
# and Availability Zone information from the EC2 API. The Region is
# treated as the datacenter, and the Availability Zone as the rack.
# Only private IPs are used, so this will not work across multiple
# Regions.
# – Ec2MultiRegionSnitch:
# Uses public IPs as broadcast_address to allow cross-region
# connectivity. (Thus, you should set seed addresses to the public
# IP as well.) You will need to open the storage_port or
# ssl_storage_port on the public IP firewall. (For intra-Region
# traffic, Cassandra will switch to the private IP after
# establishing a connection.)
# – RackInferringSnitch:
# Proximity is determined by rack and data center, which are
# assumed to correspond to the 3rd and 2nd octet of each node’s IP
# address, respectively. Unless this happens to match your
# deployment conventions, this is best used as an example of
# writing a custom Snitch class and is provided in that spirit.
#
# You can use a custom Snitch by setting this to the full class name
# of the snitch, which will be assumed to be on your classpath.
endpoint_snitch: SimpleSnitch
# controls how often to perform the more expensive part of host score
# calculation
dynamic_snitch_update_interval_in_ms: 100
# controls how often to reset all host scores, allowing a bad host to
# possibly recover
dynamic_snitch_reset_interval_in_ms: 600000
# if set greater than zero and read_repair_chance is < 1.0, this will allow
# ‘pinning’ of replicas to hosts in order to increase cache capacity.
# The badness threshold will control how much worse the pinned host has to be
# before the dynamic snitch will prefer other replicas over it. This is
# expressed as a double which represents a percentage. Thus, a value of
# 0.2 means Cassandra would continue to prefer the static snitch values
# until the pinned host was 20% worse than the fastest.
dynamic_snitch_badness_threshold: 0.1
# request_scheduler — Set this to a class that implements
# RequestScheduler, which will schedule incoming client requests
# according to the specific policy. This is useful for multi-tenancy
# with a single Cassandra cluster.
# NOTE: This is specifically for requests from the client and does
# not affect inter node communication.
# org.apache.cassandra.scheduler.NoScheduler – No scheduling takes place
# org.apache.cassandra.scheduler.RoundRobinScheduler – Round robin of
# client requests to a node with a separate queue for each
# request_scheduler_id. The scheduler is further customized by
# request_scheduler_options as described below.
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
# Scheduler Options vary based on the type of scheduler
# NoScheduler – Has no options
# RoundRobin
# – throttle_limit — The throttle_limit is the number of in-flight
# requests per client. Requests beyond
# that limit are queued up until
# running requests can complete.
# The value of 80 here is twice the number of
# concurrent_reads + concurrent_writes.
# – default_weight — default_weight is optional and allows for
# overriding the default which is 1.
# – weights — Weights are optional and will default to 1 or the
# overridden default_weight. The weight translates into how
# many requests are handled during each turn of the
# RoundRobin, based on the scheduler id.
#
# request_scheduler_options:
# throttle_limit: 80
# default_weight: 5
# weights:
# Keyspace1: 1
# Keyspace2: 5
# request_scheduler_id — An identifier based on which to perform
# the request scheduling. Currently the only valid option is keyspace.
# request_scheduler_id: keyspace
# Enable or disable inter-node encryption
# JVM defaults for supported SSL socket protocols and cipher suites can
# be replaced using custom encryption options. This is not recommended
# unless you have policies in place that dictate certain settings, or
# need to disable vulnerable ciphers or protocols in case the JVM cannot
# be updated.
# FIPS compliant settings can be configured at JVM level and should not
# involve changing encryption settings here:
# https://docs.oracle.com/javase/8/docs/technotes/guides/security/jsse/FIPS.html
# NOTE: No custom encryption options are enabled at the moment
# The available internode options are : all, none, dc, rack
#
# If set to dc cassandra will encrypt the traffic between the DCs
# If set to rack cassandra will encrypt the traffic between the racks
#
# The passwords used in these options must match the passwords used when generating
# the keystore and truststore. For instructions on generating these files, see:
# http://download.oracle.com/javase/6/docs/technotes/guides/security/jsse/JSSERefGuide.html#CreateKeystore
#
server_encryption_options:
internode_encryption: none
keystore: conf/.keystore
keystore_password: cassandra
truststore: conf/.truststore
truststore_password: cassandra
# More advanced defaults below:
# protocol: TLS
# algorithm: SunX509
# store_type: JKS
# cipher_suites: [TLS_RSA_WITH_AES_128_CBC_SHA,TLS_RSA_WITH_AES_256_CBC_SHA,TLS_DHE_RSA_WITH_AES_128_CBC_SHA,TLS_DHE_RSA_WITH_AES_256_CBC_SHA,TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA,TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA]
# require_client_auth: false
# require_endpoint_verification: false
# enable or disable client/server encryption.
client_encryption_options:
enabled: false
# If enabled and optional is set to true encrypted and unencrypted connections are handled.
optional: false
keystore: conf/.keystore
keystore_password: cassandra
# require_client_auth: false
# Set trustore and truststore_password if require_client_auth is true
# truststore: conf/.truststore
# truststore_password: cassandra
# More advanced defaults below:
# protocol: TLS
# algorithm: SunX509
# store_type: JKS
# cipher_suites: [TLS_RSA_WITH_AES_128_CBC_SHA,TLS_RSA_WITH_AES_256_CBC_SHA,TLS_DHE_RSA_WITH_AES_128_CBC_SHA,TLS_DHE_RSA_WITH_AES_256_CBC_SHA,TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA,TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA]
# internode_compression controls whether traffic between nodes is
# compressed.
# can be: all – all traffic is compressed
# dc – traffic between different datacenters is compressed
# none – nothing is compressed.
internode_compression: all
# Enable or disable tcp_nodelay for inter-dc communication.
# Disabling it will result in larger (but fewer) network packets being sent,
# reducing overhead from the TCP protocol itself, at the cost of increasing
# latency if you block for cross-datacenter responses.
inter_dc_tcp_nodelay: false
# TTL for different trace types used during logging of the repair process.
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
# UDFs (user defined functions) are disabled by default.
# As of Cassandra 3.0 there is a sandbox in place that should prevent execution of evil code.
enable_user_defined_functions: false
# Enables scripted UDFs (JavaScript UDFs).
# Java UDFs are always enabled, if enable_user_defined_functions is true.
# Enable this option to be able to use UDFs with “language javascript” or any custom JSR-223 provider.
# This option has no effect, if enable_user_defined_functions is false.
enable_scripted_user_defined_functions: false
# The default Windows kernel timer and scheduling resolution is 15.6ms for power conservation.
# Lowering this value on Windows can provide much tighter latency and better throughput, however
# some virtualized environments may see a negative performance impact from changing this setting
# below their system default. The sysinternals ‘clockres’ tool can confirm your system’s default
# setting.
windows_timer_interval: 16
# Enables encrypting data at-rest (on disk). Different key providers can be plugged in, but the default reads from
# a JCE-style keystore. A single keystore can hold multiple keys, but the one referenced by
# the “key_alias” is the only key that will be used for encrypt opertaions; previously used keys
# can still (and should!) be in the keystore and will be used on decrypt operations
# (to handle the case of key rotation).
#
# It is strongly recommended to download and install Java Cryptography Extension (JCE)
# Unlimited Strength Jurisdiction Policy Files for your version of the JDK.
# (current link: http://www.oracle.com/technetwork/java/javase/downloads/jce8-download-2133166.html)
#
# Currently, only the following file types are supported for transparent data encryption, although
# more are coming in future cassandra releases: commitlog, hints
transparent_data_encryption_options:
enabled: false
chunk_length_kb: 64
cipher: AES/CBC/PKCS5Padding
key_alias: testing:1
# CBC IV length for AES needs to be 16 bytes (which is also the default size)
# iv_length: 16
key_provider:
– class_name: org.apache.cassandra.security.JKSKeyProvider
parameters:
– keystore: conf/.keystore
keystore_password: cassandra
store_type: JCEKS
key_password: cassandra
#####################
# SAFETY THRESHOLDS #
#####################
# When executing a scan, within or across a partition, we need to keep the
# tombstones seen in memory so we can return them to the coordinator, which
# will use them to make sure other replicas also know about the deleted rows.
# With workloads that generate a lot of tombstones, this can cause performance
# problems and even exaust the server heap.
# (http://www.datastax.com/dev/blog/cassandra-anti-patterns-queues-and-queue-like-datasets)
# Adjust the thresholds here if you understand the dangers and want to
# scan more tombstones anyway. These thresholds may also be adjusted at runtime
# using the StorageService mbean.
tombstone_warn_threshold: 10000
tombstone_failure_threshold: 1000000
# Log WARN on any batch size exceeding this value. 5kb per batch by default.
# Caution should be taken on increasing the size of this threshold as it can lead to node instability.
batch_size_warn_threshold_in_kb: 5
# Fail any batch exceeding this value. 50kb (10x warn threshold) by default.
batch_size_fail_threshold_in_kb: 50
# Log WARN on any batches not of type LOGGED than span across more partitions than this limit
unlogged_batch_across_partitions_warn_threshold: 10
# Log a warning when compacting partitions larger than this value
compaction_large_partition_warning_threshold_mb: 100
# GC Pauses greater than gc_warn_threshold_in_ms will be logged at WARN level
# Adjust the threshold based on your application throughput requirement
# By default, Cassandra logs GC Pauses greater than 200 ms at INFO level
gc_warn_threshold_in_ms: 1000
# Maximum size of any value in SSTables. Safety measure to detect SSTable corruption
# early. Any value size larger than this threshold will result into marking an SSTable
# as corrupted.
# max_value_size_in_mb: 256
Hi Paul,
Can you provide the cassandra.yml file of both cassandra nodes by adding them to the post?
If its a node running on windows OS, you should be able to find thos config files on: “C:\Program Files\Cassandra\conf”