Hi, while developing a protocol in my spare time, I stumbled upon an issue.
I was using the Unicode option, as I wanted to use the € sign in one of the strings in a table.
For another table I wanted to use the name of a person followed by two numbers, example : Jan.Janssens.1.1 as the primary key.
This was a retrieved table, and the data in that table was being saved.
I found that if the total length of the string of the key is a bit higher than expected, the rows could be added to the table, but upon restarting of the element, the keys are cut off, and only one line remains.
The limit seems to be at 26 characters, from 27 onwards it cuts them off.
That is to say, it still saves the whole key, but it seems to limit the check for duplicates on 26 characters.
Now I was just wondering if this is intended behaviour or not.
In order to reproduce : make a simple protocol with a table (of type retrieved), and with the key column, and a second column of type string, with the save option.
Use the Unicode option so that the protocol uses Unicode
Make a Qaction that clears the table, and adds a couple of lines with a long primary key (27 or more characters) :
for example :
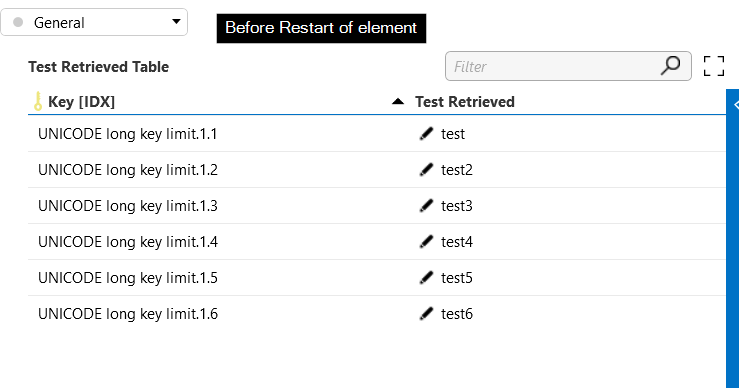
UNICODE long key limit.1.1
UNICODE long key limit.1.2
UNICODE long key limit.1.3
UNICODE long key limit.1.4
Make a button that calls the Qaction.
Now push the button, see how the rows are added.
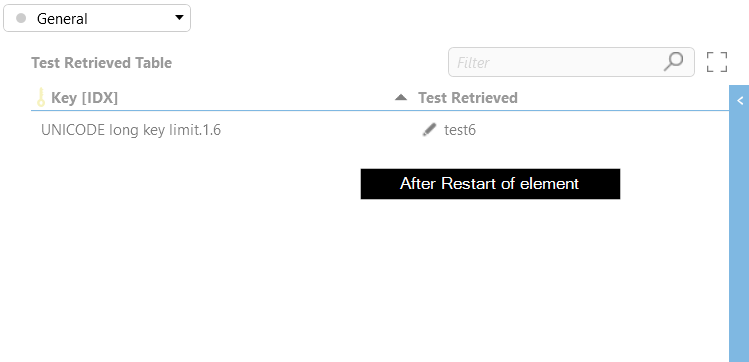
Next, restart the element.
Notice how all but one rows disappear.
Hi Filiep,
This is indeed expected behavior.
In the database, the first 100 bytes of a primary key must be unique.
By default, UTF-8-char encoding is used, which encodes a char in as many bytes as required, with a max of 4. Chars from the ASCII char set are encoded using a single byte, so if your key is only made of ASCII chars, the first 100 chars must be unique. In a worst-case scenario, all chars take up 4 bytes, meaning that the first 25 chars must be unique.
When using the Unicode option, chars typically take up 4 bytes, meaning that the first 25 chars must be unique.
In any case, note that for performance reasons, the Primary Key should always be as small as possible and ideally should be a number.
When your identifiers become relatively large, it’s better to create primary keys yourself (start with ‘1’ and increment the value for each new row) and create a mapping between those primary keys and your identifiers.
OK, it’s a pity that you cannot override this limit for a particular table.
I will have to do some rewriting for my protocol then.
Should there not be a warning when you go beyond that 25 character limit for your keys?
I do not get any duplicate key messages, and it seems that the whole key is saved, only the checking part is where the limit of 25 bytes exists.
I fully agree with your suggestion of generating a warning or error log when one goes beyond the 100 bytes for a primary key so feel free to make a feature suggestion there.
Regarding the configuration of such limit, I’m not sure if it’s worth making such change. In then end, it’s still recommended to keep it as small as possible and making the mapping between an auto-generated numeric key and your identifier is not that much work. Having it configurable would feel to me like opening a door leading to inefficient implementations so I’m currently not convinced that we should go there.
See following sections in our protocol development documentation for more info:
– https://docs.dataminer.services/develop/codingguidelines/Protocol/Primary_keys1.html
– https://docs.dataminer.services/develop/devguide/Connector/UIComponentsTablePrimaryKeys.html