I am evaluating the Media Ops as a candidate for a project and I think it will require a large number of resources in a pool that need to be managed over a timeline via scheduled jobs. For example modelling the input and output ports on a matrix switch where each input/output combination would be a single resource that could be connected at a point in time. If the switch was 100x100, so a potential 10000 individual resources. Is this viable? i.e. would the system performance suffer with such a large number of resources?
Hi Mark,
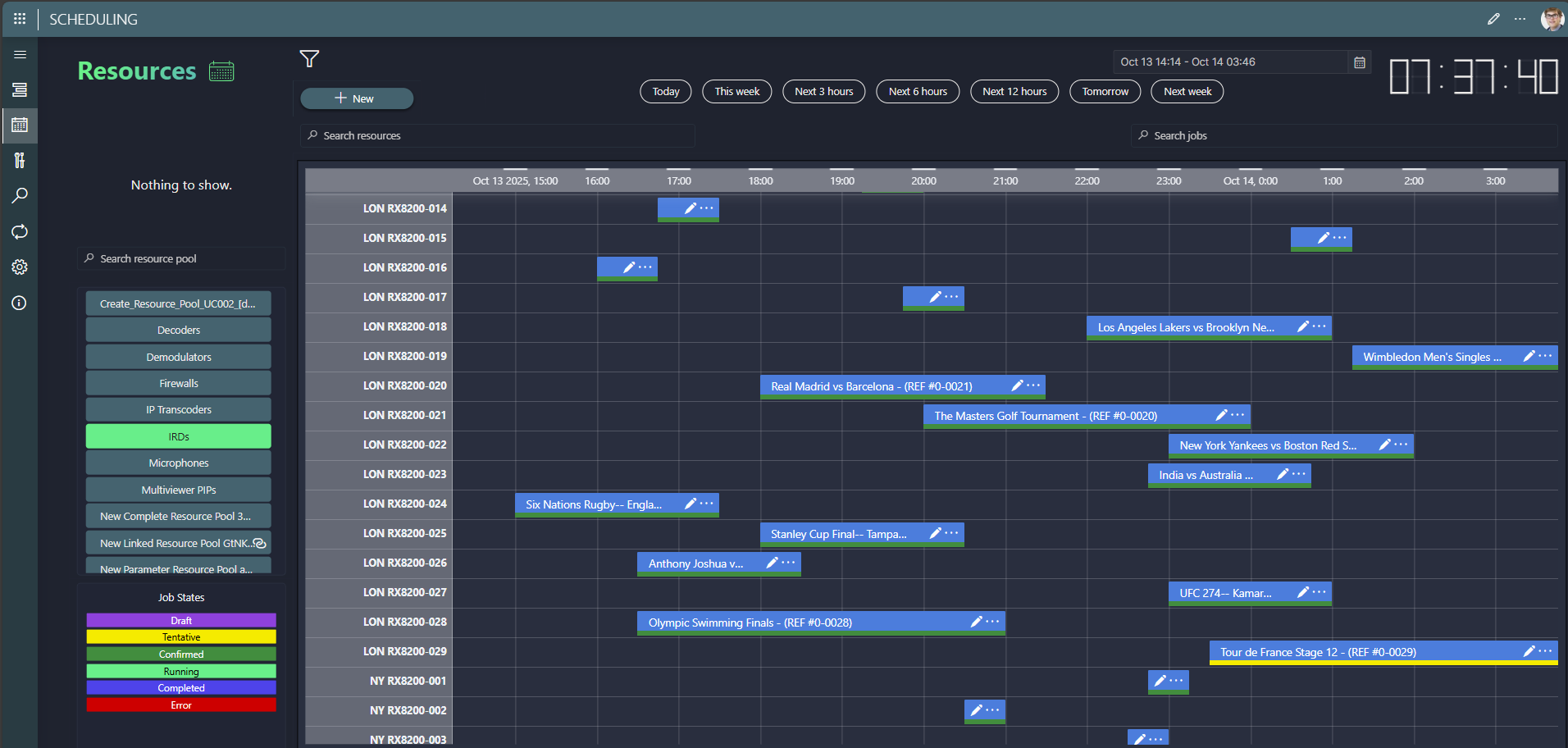
A resource pool is used to define a function, we use it to build workflows (e.g. first a node of camera pool, then a video processor, ...). You can select a resource from that pool that is available (matching capability and capacity requirements) for jobs. From the resource view in Scheduling, you can see on a timeline the jobs in which the resources of the pool are used (see below screenshot). The more resources you will have in one pool, the more the view might be cluttered for operators. Typically, the outputs on a matrix are reserved (assuming you can route the input to multiple outputs). If you have a naming convention, you can filter down the resources in the timeline. But you could also consider splitting the outputs into multiple pools (e.g. outputs for the Studio, ...). This way it might be easier for operators to digest the number of resources, but they would need to navigate through different pools. Note that you can still create one pool that contains all outputs as well (resources can be in multiple pools). Below you can find the numbers to which we tested the solution. Let us know if you are planning to go over these numbers. If you are in contact with a Salesperson of Skyline, feel free to request a meeting to discuss your use-case into more detail.
The numbers on which we tested at Skyline:
- Total #resources: 20k
- #resources/pool: 5k
- Jobs/day: 1k
- max concurrent jobs: 1k
Hi Michiel, thanks for the metrics, just one further question – did the system still have potential to handle more resources at the limits of your tests (i.e. was it still performing to an acceptable level) or was it starting to struggle with these volumes?
We did see that loading the components in the LCA framework is taking longer on larger scale (more nodes in a job, more resources/pool, …). As there are too many variables (e.g. CPU/mem, network delay, scale, …), it is not possible to give numbers that you can rely on. Initially, some components did not load within acceptable time. That was why we introduced lazy loading (e.g. for this resource timeline). This means the first page of resources will load quickly, then you need to scroll down to load the next batch of resources. The page itself will load within acceptable limits, but if you would add up the time it will take to scroll completely to the bottom it might not be within acceptable limits for an operator. That is also why filtering options are available to find the right pool or resources faster. In addition, if there are simply too many resources and/or jobs in the component you will get a warning that not all of them can be loaded to avoid that the browser starts to crash. Then only the first 1000 biggest jobs will be shown and the first 500 resources of the pool. Note: not advised, but it is possible to increase those limits (if your machines can handle it of course).
just to note – I used this example to create a large number of resources, in reality I would just manage the input and output ports as resources and store the allocation against each other as a property of the booking/job.