Hello Dojo
I need some clarification and advice on Usage based model. Here is an example:
If a customer has 5x VMs running in cloud (each VM runs two transcoding services), plus 5x encoders and 5x decoders running on prem.
For “data collection”, How many “managed objects” should I choose? 20 or 15? In this part, do we consider the complexity of the objects (or products)? Like some producst have thousands of parameters in single unit but some only have dozens.
For “connector service”, I should choose 3, right?
For “cloud servies”, how can I estimate the storage used per month? If this DTaaS is used for monitoring and control only, how many GB/month is suggested for reference?
For “automation and orchestration”, if only monitoring and control (setting parameters) is used, should I leave it as “2K” (0 credits/month)?
Thanks in advance
Wayne
Hi Wayne,
Interesting example, when you talk about virtualized/containerized infrastructure and cloud-based functions the answer is not always black and white, it depends on how the solution is implemented and its objective.
Let’s start with the onprem: you would have 10 MO for the encoders and decoders.
For the VMs you could have one MO for VMware reporting data about all virtual machines, one MO per transcoding service, but it’s also possible that the transcoding service is a single MO containing tables with information about the transcoding services.
Let me give another example: the case below shows one MO per server (ILO), one MO per each K8S container, node, and pod, as well as one MO per each encoding and decoding function. Because this solution is about orchestration, it made sense for the user to go more granular and implement separate MOs per service (in DataMiner these are represented by Virtual Elements (DVE)). Using the same infrastructure but with a use case for health monitoring only, you could have a single MO per K8S cluster and a single MO for the Encoding Services, as these are usually reported by a single data source. 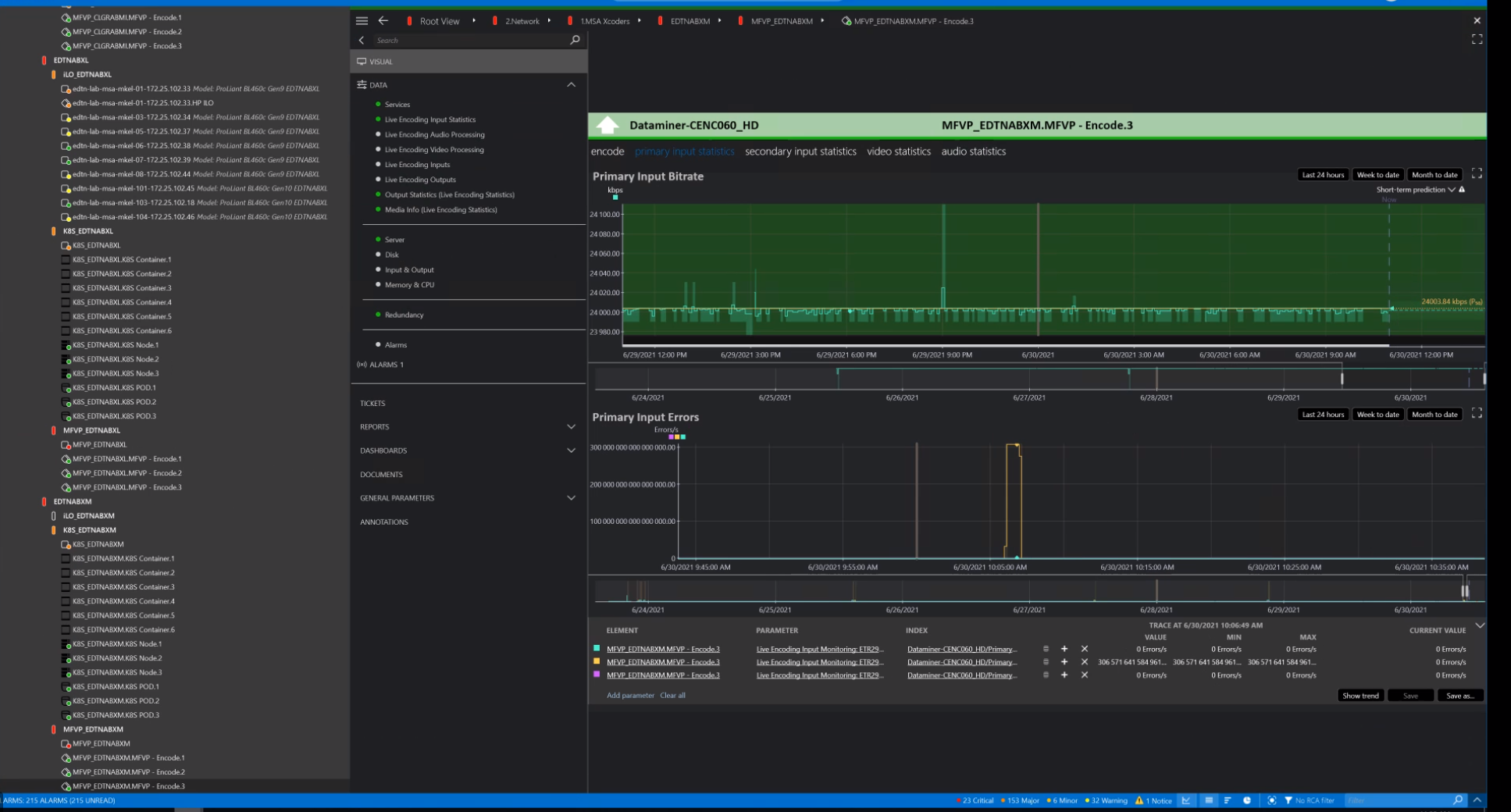
Connector services: you need to identify your data sources, which could be an API for the encoder, one for the decoder, one for the VM environment, and then one for the transcoding services, if you want to collect information about those services beyond what’s reported by the hosting infrastructure.
Cloud services: this is not about storage but rather about traffic for dataminer.services, like data sharing.
automation and orchestration: that seems to be a good estimate. I usually think in smaller time blocks – how many runs am I expecting per hour? how often will they run? What kind of triggers do I have (e.g. could be a script that creates tickets for correlated alarms or manually triggered scripts to run some tests)? Is it full-time, working hours, weekends…?)