We have a system that is using a data distribution parameter from one element to another. The logic is as follows:
SNMP table for element 1 (HTO) is polled and stores all columns for each row into a parameter of type distribution: 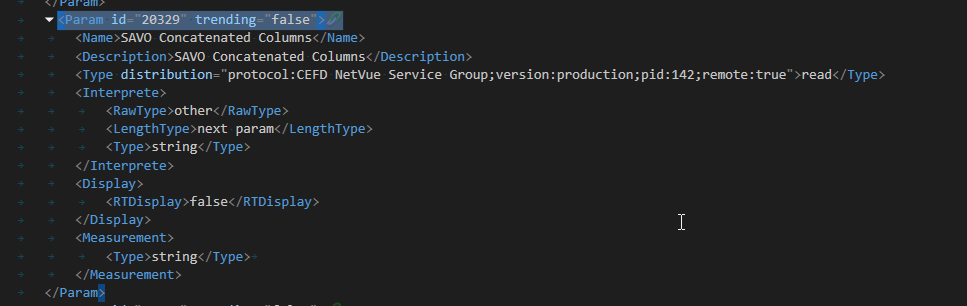
Element 2 (NetVue Service Group) receives this in a parameter that is the column of a table:
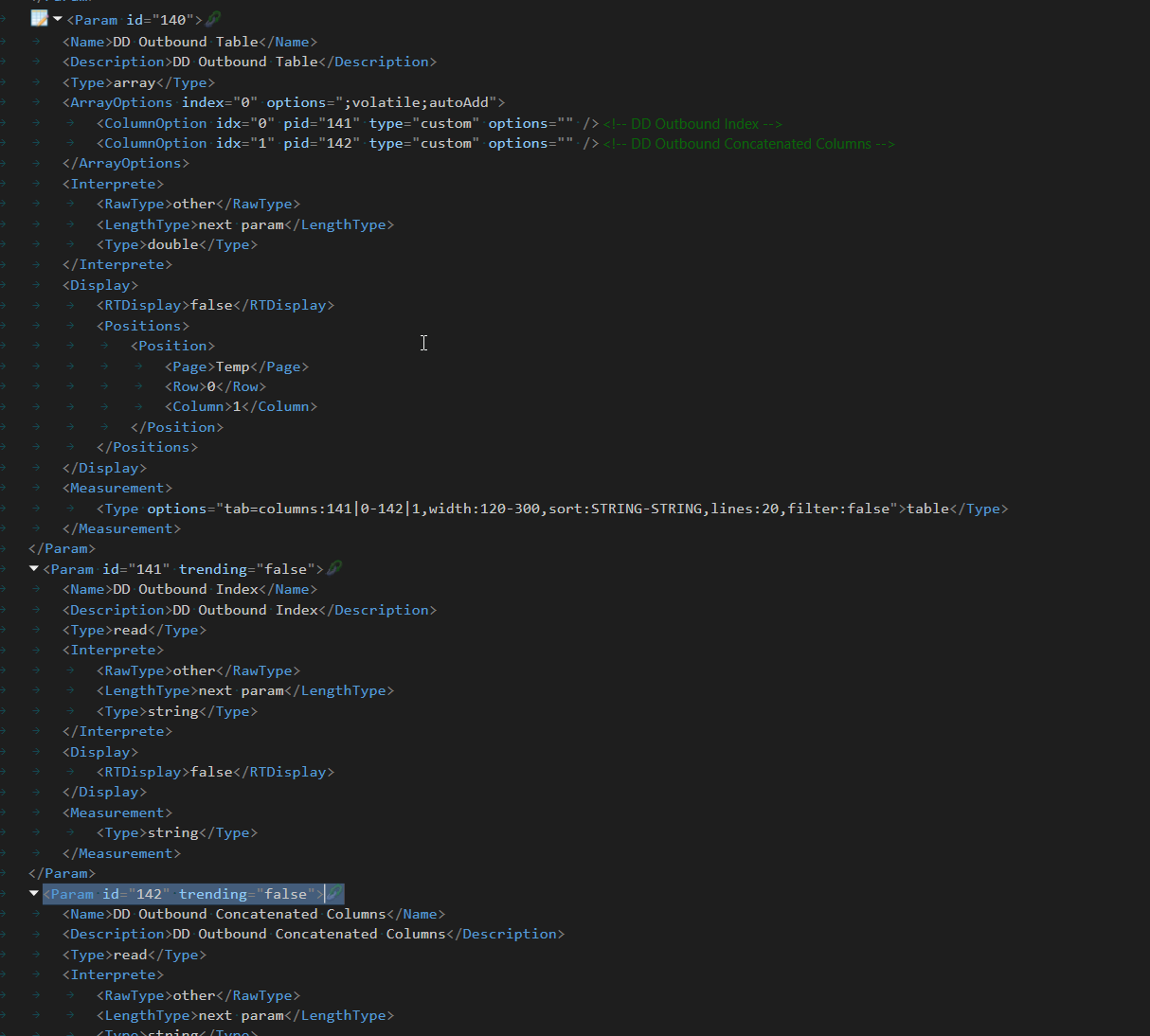
This triggers a QAction that parses the parameter and sets or adds the row.
It’s important to know that element 1 should have 1 row and element 2 can have multiple. Think of element 2 as a sort of manager for multiple element 1’s.
The problem I’m having on the system is that there are manager rows randomly dropping to 0 despite the SNMP data not dropping:
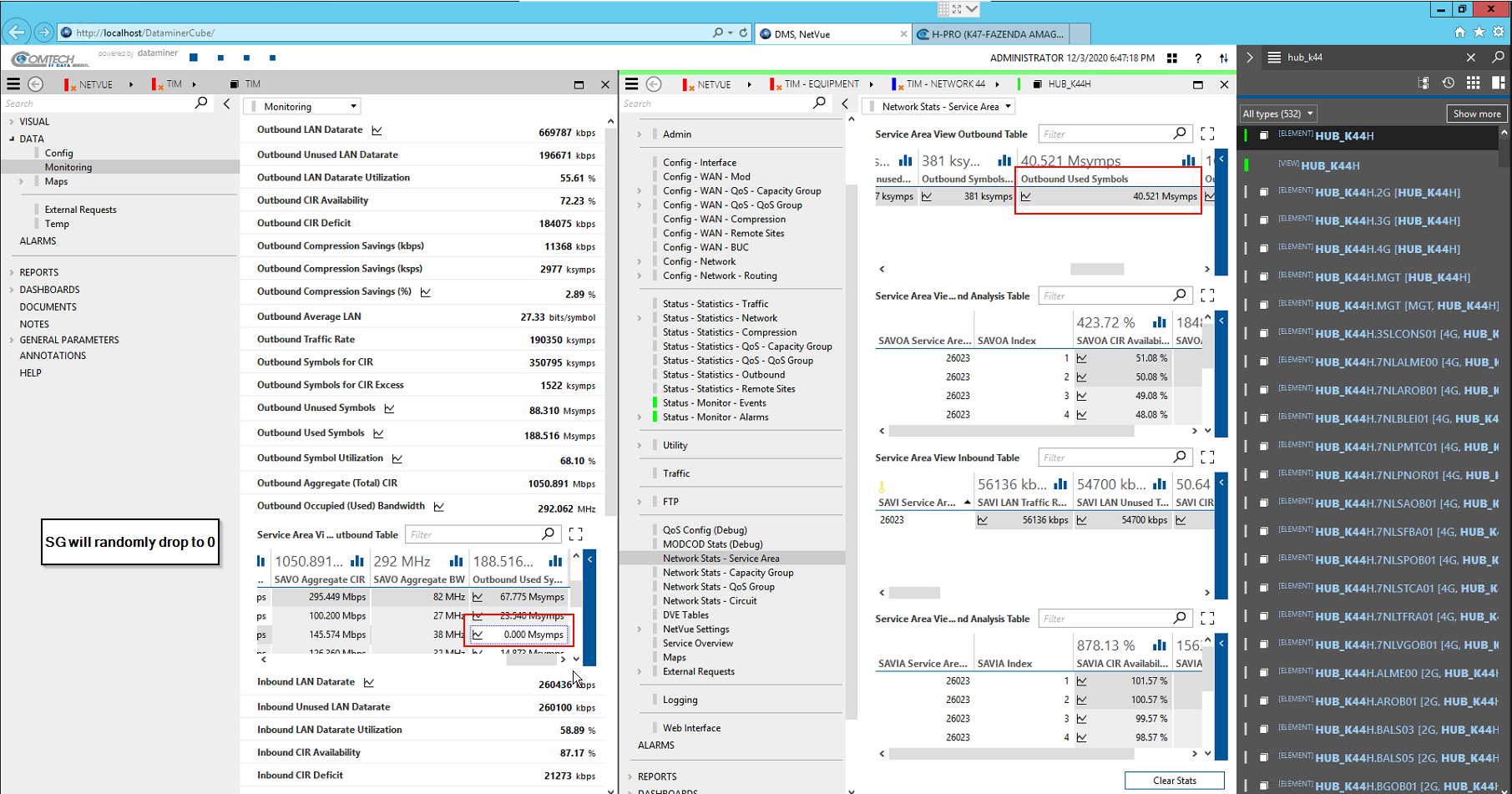

It drops to 0, for a few seconds, then goes back to the correct value.
This is resulting in incorrect trend graphs when you trend on “manager” level.
Any idea what could be causing this? I have attached the task which includes the existing QActions for storing and parsing the column, as well as the associated protocols.
https://collaboration.dataminer.services/task/140273
Feel free to message me for further clarification. Thanks in advance.
As far as I understood the description, element 1 (HTO) is composing the data to be sent with a QAction (kind of a serialized string), element 2 (NetVue Service Group) needs to process the incoming data (deserialize) also through a QAction? Data distribution is used to pass the serialized data between the elements. If this is the case and driver modifications are allowed to perform an investigation then I would add the possibility to enable logging where you can write out exactly what is being sent out and what value is being received by the QActions, this way it can be compared. If it sends out value 0 then the source element is to be further investigated, if it receives a value not 0 but fills in 0 then there is something wrong with the parsing part. Is it sends out value not 0 but receives value 0 then it would seem strange that a serialized string gets changed when being transported (or 2 source elements could be targeting the same destination row and overwriting each other).
Besides the original problem, if the intention here is to only display the parameter values then table views would have been a better implementation. The advantages are that the data does not need to be sent from one element to another and the trending is also not duplicate has the element 2 has direct access to the trending of element 1, this is seamless. If calculations need to be done for a higher level then merging/aggregate actions could be used on the source elements
Hi Alex, table views is a different concept. There is no data being passed between the elements anymore, that is the main plus. A table view is being constructed whenever the client is eg opening an element card. It’s basically saying when opening the element card then get me the data from these table column(s) from these element(s). So it’s a view on the tables that is being created and you’re able to see the alarm state and able to access the trending. The construction of the table view only happens on request when somebody is actually looking at the data, that is the main benefit of table views: no constant distributing data, no duplicate trending that needs to be stored, no duplicate alarming. For the end user, they’re not aware that it’s a table view, for them they’re just looking at a normal table.
Hi Laurens,
Thanks for the thoughtful answer. Could you possibly elaborate on the table views implementation? Would this be possible with inter-element communication? Ie, we need to keep the flow the same where the source element sends data to the destination element.