Hi, in a project that we're working on, DataMiner is being used to replace a legacy fault management system. We have been provided some numbers around alarming that we should expect:
1) the total number of alarms currently being stored and maintained by the legacy fault management system. Most recent number indicates that this is around 25 million alarms (both historical and active) out of which about 10 million are clear alarms.
2) an alarm rate of between 4000 - 12000 on a typical day maxing out at 83,000 on at least one day in the last 3 years.
Can we have some advise around how we can use these numbers to estimate the storage requirements (Elastic and Cassandra)?
We would also like some guidance around whether the rate of alarms provided is within the limits of what DataMiner has been validated to handle.
Hi Bing,
Here are some alarm metrics i have from a production system which has been running for approx. 10 months on the architecture where the DataMiner cluster (6 nodes - Windows Server OS), the elasticsearch cluster (3 nodes, Red hat Linux) and cassandra cluster (3 nodes, Red hat Linux) is hosted in a vm environment where all of the nodes have their independent VM guest image:
Currently the elasticsearch cluster is holding approx. 176.000.000 unique documents. (a document compares to a row in a table based database) this is resulting in a total dataset size of approx. 330 GB's which is spread over 3 nodes, so each node is approx holding 110 GB's of data currently on disk.
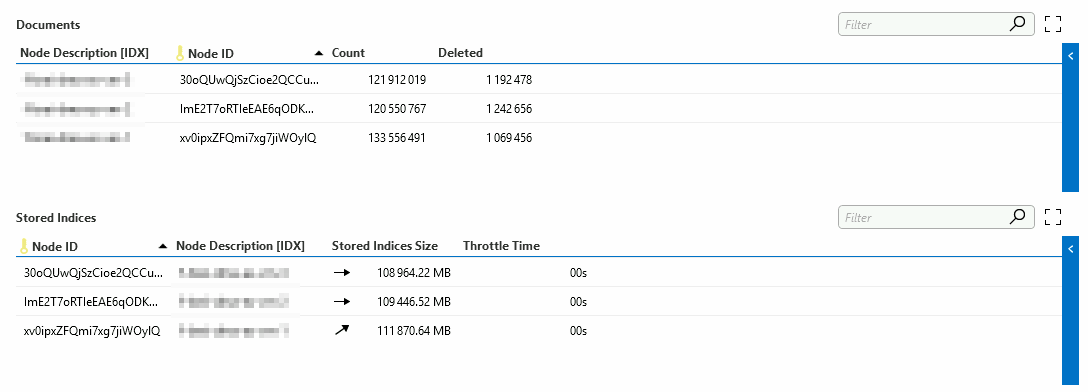
There's quite a bit of alarm and info event activity on this particular platform. A last 24hr count of all activity tells me that there were 747312 alarm records / documents added:
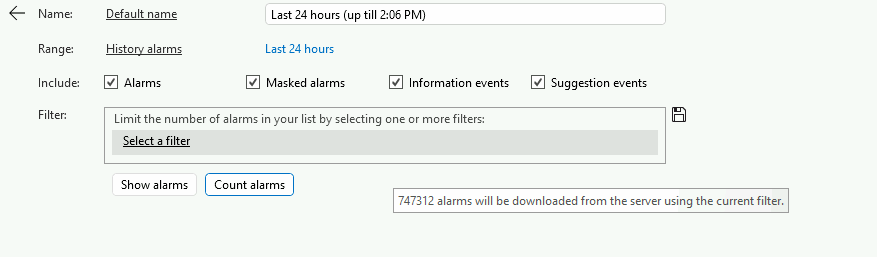
The total stored index size on the cluster currently increases with approx. 1.7 GB's a day. which translates in an increase per node of approx. 600 MB's a day.
Hi Jeroen, thanks for sharing what is being observed from an actual production system. It appears that the 6-node DMS is capable of handling ~750K alarms per day. That averages out to about ~125K alarms per day per node which is above the alarm rates in the scenario I provided.