Hello Dojo,
We had an issue where a failover agent suffered a complete hardware failure and needed to be reinstalled on a new machine. The backup agent was reinstalled on new hardware, but did not have a backup to restore, so a fresh 10.2 installation and upgrade to 10.2 CU11 after joining this new agent to failover we noticed a schema mismatch, after it was reported that elements were no longer working do to the previous schema being lost and a new one created.
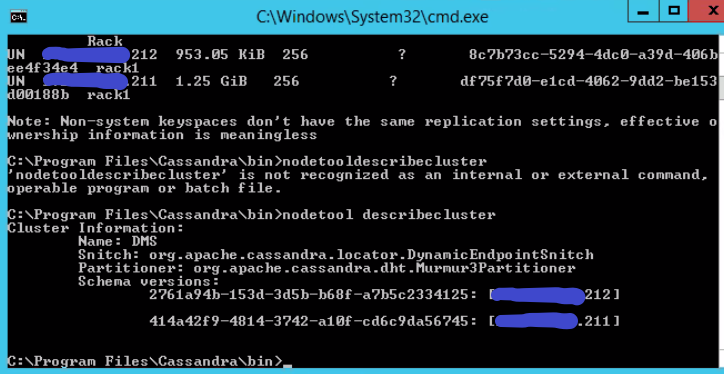
I have attempted to resolve this mismatch by doing a nodetool drain and rolling restarts on both nodes. When that did not work we ended up breaking failover on the primary agents cube from the failover status window, reinstalling again the backup agent, setting the primary node back to localhost and from the primary node executing a nodetool removenode of the backup node as it still remained in the nodetool status after breaking failover.
After rejoining the backup agent in failover, we again have this same issue as above. It seems as though the schema conflict resides in the primary node somewhere but I am unsure how to resolve it. I am not sure where this schema mismatch could be stored in the primary node and where to go from here.
Thank you in advance for any insight and info!
Hi Ryan,
When DataMiner starts it will create the tables if they don't exist yet. When a new Cassandra node is being added to an existing cluster, you should point it to the seeds of the existing cluster to ensure the schema is known to the new node. When the node itself is a seed it can start without contacting other seeds. Most likely, the failover agent added a blank Cassandra node as seed. When DataMiner communicates to it just after it starts it will not yet have the schema, so it will create the needed tables of the same name overwrite the existing tables.
If you end up in the situation where you have two folders of your tables with a different ID and you want to restore the data, you will need to figure out first which one is now being used by the cluster. If you still have one node using the correct tables (you can see the ID used in the tables table in the schema keyspace). You could stop the Cassandra nodes that are using the incorrect ID and add those again after cleaning them (SSTables, commitlogs, hint files and cache) and set seeds of nodes with the correct schema without setting itself as seed.
If the new tables are already accepted by all nodes, then you can restore the old data by copying the SSTables from the old folder to the new one and restarting Cassandra.
Hope this helps.
In regards to, “When a new Cassandra node is being added to an existing cluster, you should point it to the seeds of the existing cluster to ensure the schema is known to the new node.”, when you configure a failover agent from the cube, it automatically adds both IPs of the failover agents as seeds on the primary and backup cassandra.yaml files. Is this a potential software issue or is it handled differently when the node is first joined and only after they are joined does the software append the yaml to include both IPs?
Depends a bit on how the software is handling adding a failover (they could wait until after the node is fully added to the Cassandra Cluster before connecting to it for example). Ideally, you do not configure a new node as a seed to prevent this situation, so you could see this as a bug.
Running a nodetool status on the different nodes during the process can also help you to identify what is going on.