I have a DataMiner cluster and Cassandra and Opensearch DB clusters. The machines are divided into two geographical data centers, also there is one additional coordinator node for Opensearch.
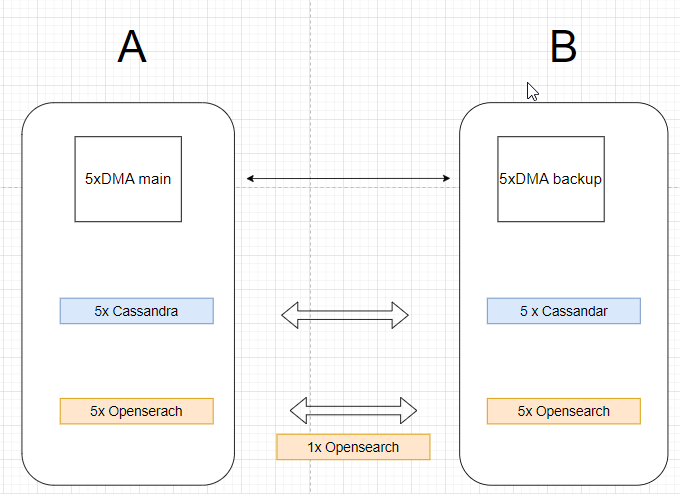
Cassandra is one cluster internally divided into two data centers, A and B.
Opensearch is one cluster divided into two zones, A and B.
I want the main DMA agents in location A to first write to databases in location A, and if those databases are not available, write to databases in location B.
And DMA agents in location B should first write to databases in location B.
How can I achieve this? Please give me some hints
Can I use this option for opensearch in my case if I got one cluster?
https://docs.dataminer.services/user-guide/Advanced_Functionality/Databases/Indexing_database/OpenSearch_Database/Configuring_multiple_OpenSearch_clusters.html
Hi Piotr,
First of all the link you provided is if you use different OpenSearch databases. This is mainly if you want an offload database to do some additional queries on (for example use grafana or something).
In your case, you're using allocation awareness.
For Cassandra and OpenSearch, it's not possible to give up your preferred nodes to connect to. DataMiner will try to connect to all IP's mentioned in the db.xml and the first one who response, DataMiner will connect with.
In an ideal world, this would mean the database that is closest off course, however there's no guarantee in this.
You can work around on this by only referring to the IP's that you want. This would mean that on Cluster A you refer to the IP's of the Cassandra nodes in Cluster A, and same for OpenSearch. The downside of this is, that if all nodes would be down in Cluster A you have to manually adjust the IP's to refer to Cluster B and restart your DataMiner.