The Apache Cassandra Cluster monitor element performs some system checks and it, suggests the following: “xxx tables were not repaired within the tombstone removal period. Please increase the gc_grace_seconds or the frequency of the repairs”
The problem here is that the gc_grace_seconds setting came from dataminer which created the table (in this case with gc_grace_seconds =14400 seconds or 4 hours), and the time it takes to repair this table (in this case trend_data_long) takes ~2.5 – 3.5 hours according to Reaper.
This would mean that we would almost permanently have a repair running for this table to keep up with the gc_grace_seconds parameter.
Is this intended behaviour?
Are there any other options to prevent this warning from popping up?
Is it bad for the system if we don’t repair the database as often?
Kind regards
Hey Stijn,
Cassandra Cluster trend tables use TimeWindowCompactionStrategy. TWCS tables should not be included in automated Reaper repairs. Our user guide provides repair recommendations here: Keeping your nodes repaired (see NOTE).
Is blacklistTwcsTables set to true in your cassandra-reaper.yaml? You can also explicitly exclude TWCS keyspaces from Reaper repairs using the excludedKeyspaces setting in the yaml.
To prevent your cluster monitor element from checking tables that aren’t scheduled for automated repairs, exclude these tables from repair checks on the Tables page of the element.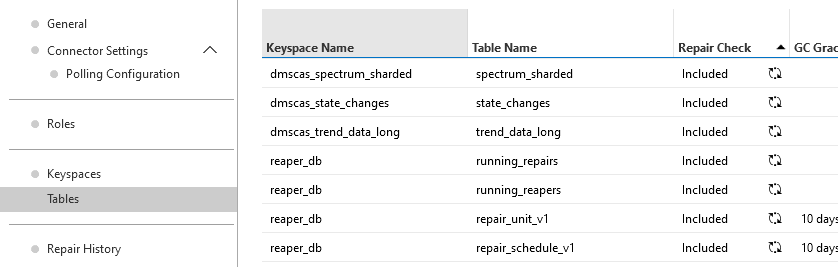
Thank you very much! Must have looked over the note in the docs, my bad!