Hi,
I need to fetch api/{id}/service for id = 1…8. Each call returns a JSON Service object for that single ID only, and I want my DataMiner array-parameter table to show one distinct row per ID. Currently my implementation produces only one row (or eight duplicates) instead of eight unique rows. What’s the simplest way to drive one row per API call—either in a single QAction or via an array-bound session—given that each response is limited to that one ID?
Hi Rachel,
I myself am only familiar with the QAction approach, so I'll only comment in that regard.
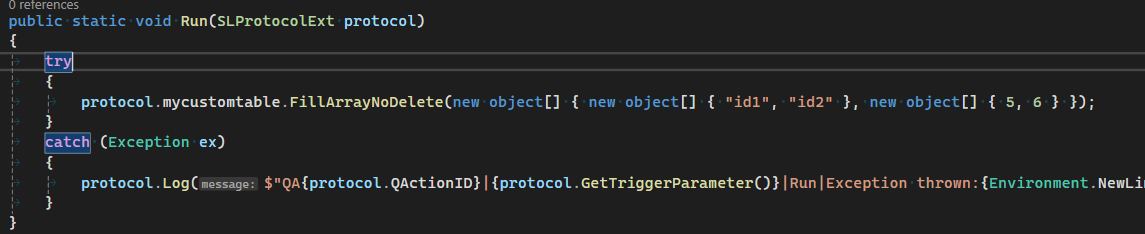
In my opinion, the easiest way to do this after performing the API call is with the FillArrayNoDelete function, ensuring that the primary key of every entry is unique.
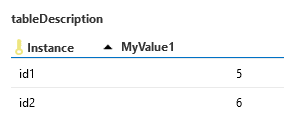
In your case the id (1..8) serves this purpose.
Alternatively, you could also use the FillArray function if you want to remove entries once the primary key is not present anymore in the source where you fetch your data from.
Based on this primary key DataMiner will either add a new row (if no entry present with that key), or update the existing entry with that primary key.
As visible below in the screenshot: The FillArrayNoDelete method expects a 2d array. Every array in the first dimension represents a column. See the screenshot of the table below to see how this is formatted.
The most efficient approach in your case will be to first retrieve your 8 rows and perform 1 "big" FillArrayNoDelete with all the data (since you only have 8 rows).
Bonus tip: I prefer using the "SLProtocolExt" type (See my screenshot below, pay attention to the type that's specified for the "protocol" object as an argument of the "Run" function).
Using this has the advantage that the table name is made available directly as a property of the "protocol" object. In my case, the name defined for my table in the protocol.xml is "MyCustomTable", which is translated to "protocol.mycustomtable" in the QAction.
Hope this helps!
Kind regards,
Regarding the tip of using SLProtocolExt, I'd recommend to read this:
Thank you Bram and Jose. The FillArrayNoDelete worked.
Hi all,
To complete this implementation, it would be beneficial to include a mechanism that ensures the table does not grow indefinitely over time.
Ideally, the best approach would be to retrieve all data and use a standard FillArray operation, which automatically handles cleanup by replacing the entire table content.
If that’s not feasible and you're using FillArrayNoDelete, I recommend adding a "Last Received" timestamp column to the table. This would allow you to identify and remove outdated rows after a defined period, helping to keep the table size under control.
Kind regards,