Hi,
Is there a limitation on the amount of elements (complete/all parameters) you can add to a service?
Can you add 50/100/500/1000 elements to a service, what would the impact be on DataMiner?
Hi Tim,
To investigate the impact on DataMiner when a service contains a specific number of elements, we decided on a strategy with 4 test cases: a service with 1 element (TC1), a service with 10 elements (TC2), a service with 100 elements (TC3), and a service with 1000 elements (TC4). We tested this on a DataMiner Agent using version 10.1.12.0-11212, with a server with 10 GB RAM, a Xeon CPU E3-1220 v3 @ 3.10GHz, and a Windows Server 2012 R2 64-bit operating system.
In each test case, at a 5-minute interval, we gathered several metrics for the system to use as a baseline without any interference from service creation, so we could measure the impact when executing the service creation and deletion. Using the same time window, we then created the service with the specified number of elements. After gathering the metrics, we deleted the service again with a waiting period of the same window to avoid corrupted/biased data when we harvest the metrics.
This is the calculation we used:
- Delta TC = Test Case result – Baseline of Test Case
- Relative Delta TC = 100 * (Test Case result / Baseline of Test Case)
Below, you can find the graphs using the Delta TC result with the following KPI metrics: VM size, handles, and threads. The CPU KPI is not displayed as the impact there was almost null: for all test cases, it showed a flat line for all processes (except for SLAutomation, caused by us recording the data). To guarantee a certain granularity and confidence in the results, the number of samples taken for each test case is similar, around 100 cross-sections.
The DataMiner Agent was empty, and it was only running our performance and impacting test scenarios. We used elements with average specifications, without any alarm or trend template assigned, in order to have an element configuration replicating those seen around the DataMiner world as much as possible:
- 100 single parameters
- 1 table with 10 columns with 500 rows
- 1 table with 5 columns with 1000 rows
- 1 table with 20 columns with 19 rows
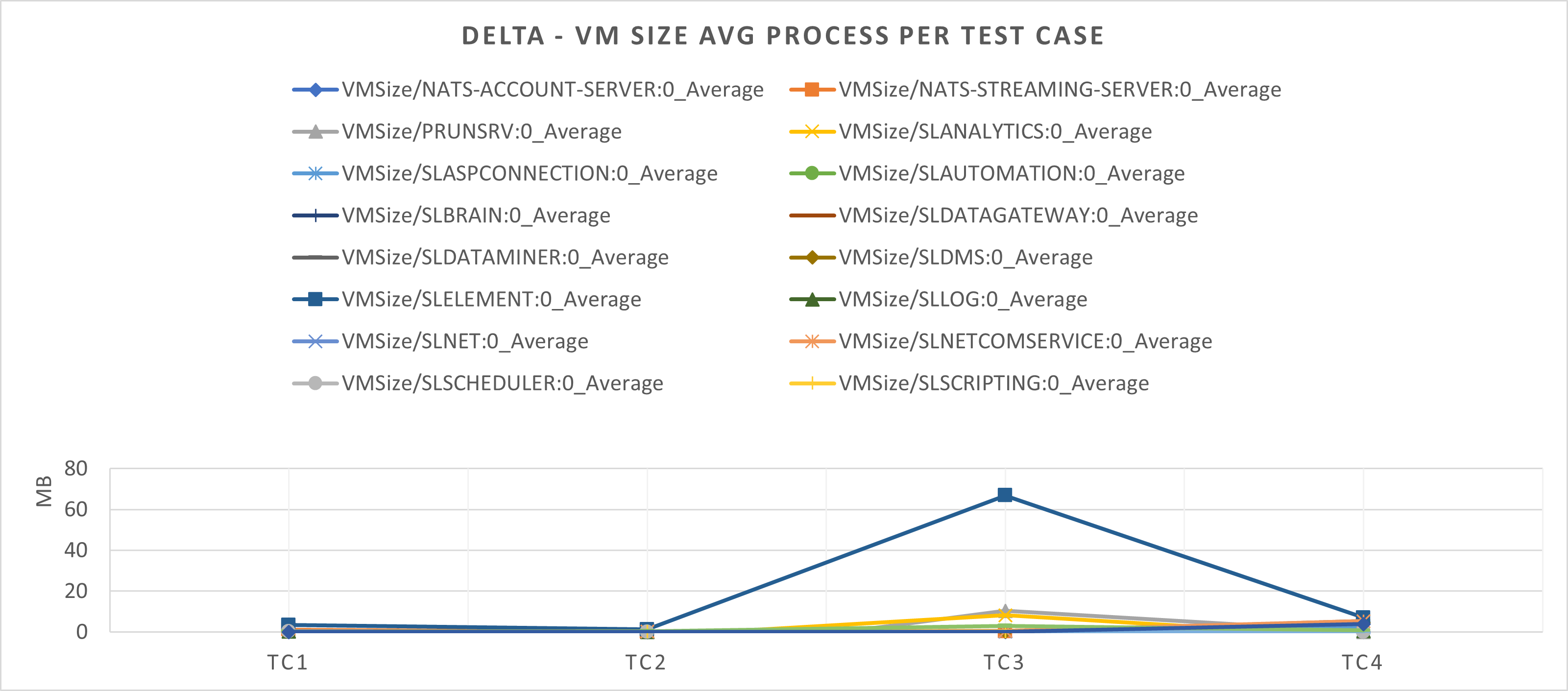
The VM size shows some small increases, but these remain expected and controlled for all processes. The most significant impact is the higher jump from TC2 to TC3 for the SLElement process. We can therefore see a clear impact on SLElement when a service with 100 elements is created, using almost 70 MB more compared to the baseline. However, when we increase this number to 1000 elements, we can see this stabilizing with a result that is lower than TC3 but, as expected, higher than TC2.
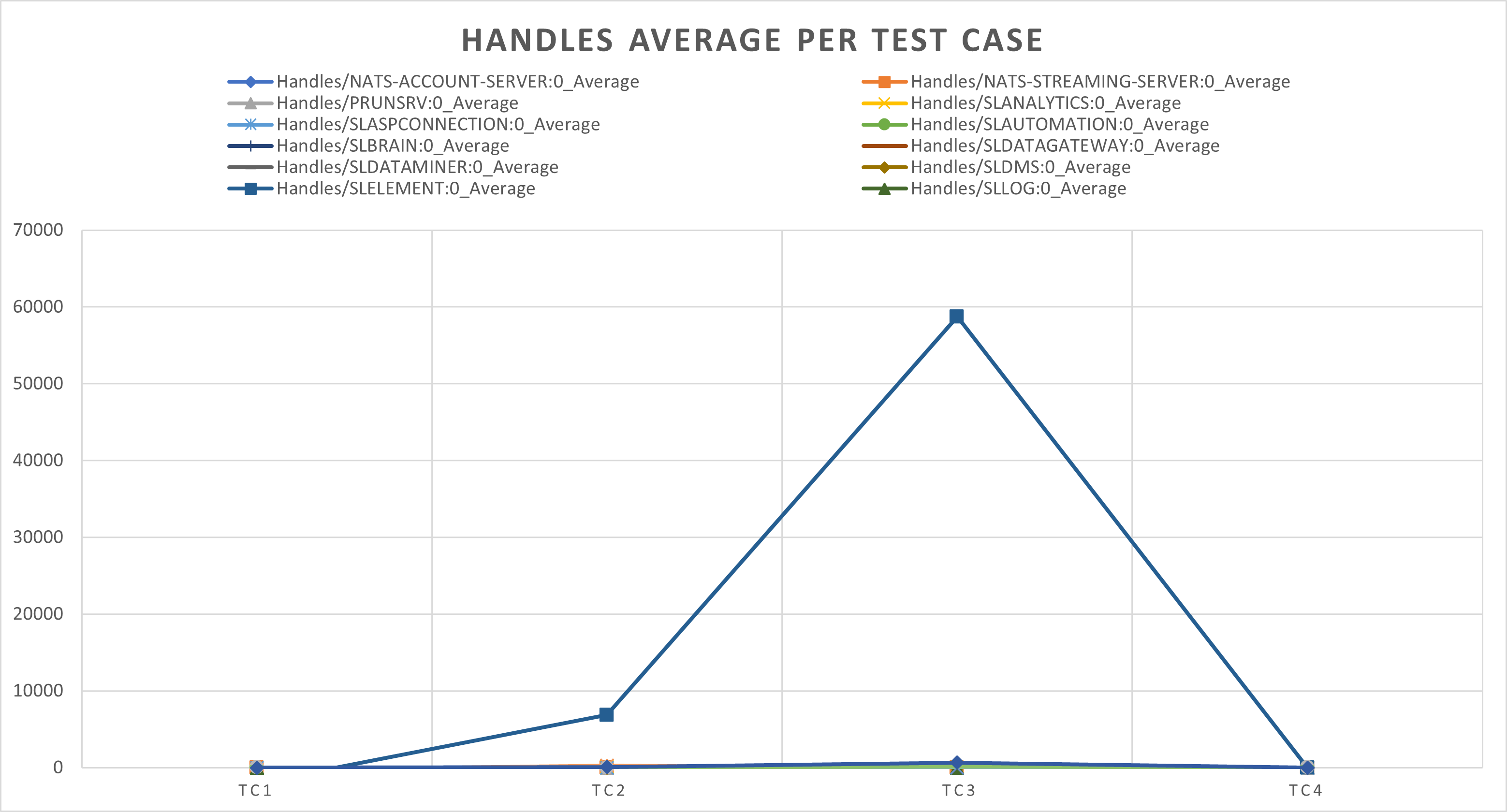
Based on the VM Size results, we could already expect that the handles for SLElement would be where the largest impact would show up. And indeed, we can see a clear linear curve when we continue increasing the number of elements in the service. However, an interesting thing that requires further investigation is that the handles for TC4, with 1000 elements, become even lower than for TC2. This leads to the possible assumption that the process starts to be scalable with other processes and the garbage is cleaned up quickly.
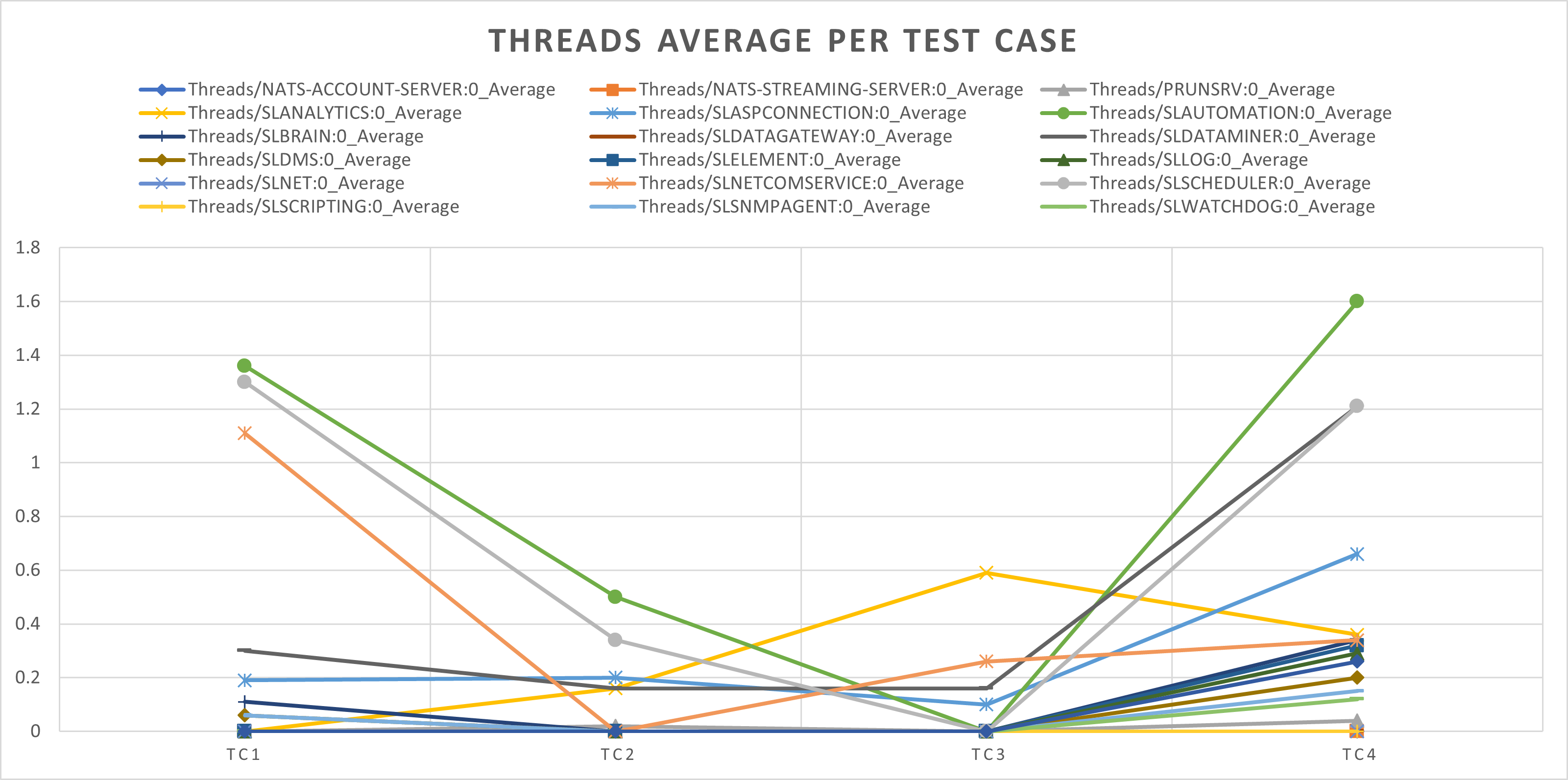
The increase for the threads is residual since it is lower than 2 threads when compared with the baseline for each test case.
During each test case, we also collected metrics related to the time needed for DataMiner to create and delete the service:
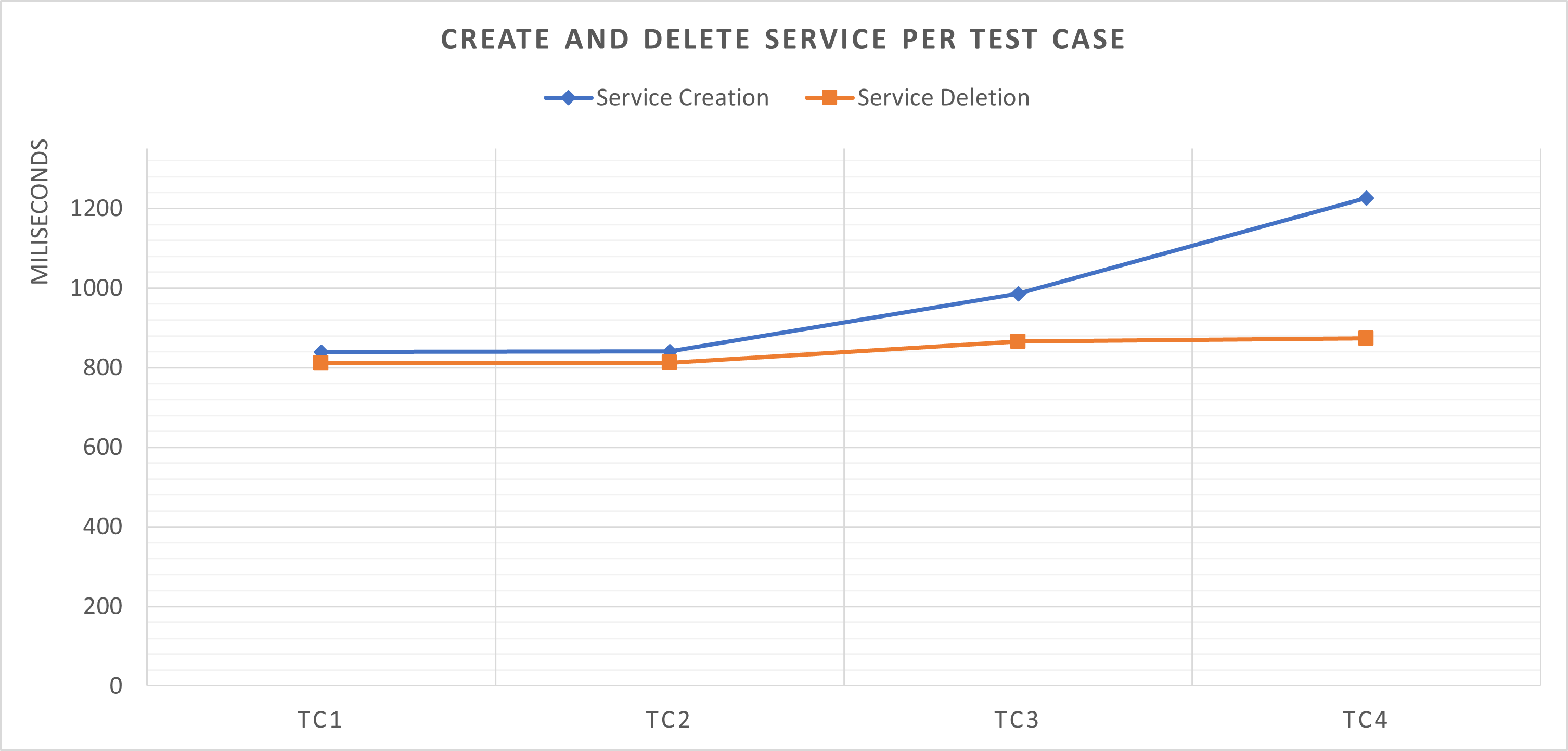
The creation and deletion always takes less than 1 second, except in test case 4, where the creation takes longer. The time needed follows a linear scale: the more elements need to be included in the service, the longer it takes to create or delete the service.
In conclusion, when analyzing the graphs, we can see that when the created service includes 100 elements, the impact on the system, or more specifically on the SLElement process, is an increase of VM size of 70 MB, and the handles required by that process also significantly increase. There is no simple root cause that explains why this occurs on TC3 with 100 elements but we don’t spot this when increasing the number to 1000 elements. A reasonable explanation can be that the garbage collector is triggered to manage and optimize the memory better, reducing cache and possible lingering objects in memory. With 100 elements, this process could take more time to be triggered. Note that the investigation above only looks into the impact of service creation/deletion with an increasing number of elements. Other approaches could lead to different behavior with a different impact on the DataMiner processes.