Nodetool status flowchart
graph TD
%% -------------------------------------------------------------------------
%% Cassandra flowchart - Nodetool Status
%% -------------------------------------------------------------------------
%% -------------------------------------------------------------------------
%% Define styles
%% -------------------------------------------------------------------------
classDef classAction fill:#dddddd,stroke:#dddddd,color:#1E5179,stroke-width:1px;
classDef classActionClickable fill:#999999,stroke:#999999,color:#ffffff,stroke-width:1px;
classDef classDecision fill:#4baeea,stroke:#4baeea,color:#ffffff,stroke-width:1px;
classDef classExternalRef fill:#9ddaf5,stroke:#9ddaf5,color:#1E5179,stroke-width:1px;
classDef classSolution fill:#58595b,stroke:#58595b,color:#ffffff,stroke-width:1px;
classDef classTerminal fill:#1e5179,stroke:#1e5179,color:#ffffff,stroke-width:1px;
%% -------------------------------------------------------------------------
%% flowchart structure
%% -------------------------------------------------------------------------
HOME([Start page <br/> Troubleshooting Cassandra])
START([Nodetool Status])
END([End])
Action_NodetoolStatus[Perform Nodetool Status command.]
Action_CassandraLogsExceptions[Check Cassandra logs for exceptions.]
ActionClick_RunRepair[Run repair command]
ActionClick_GarbageCollection[Check Cassandra logs for garbage collection.]
ActionClick_CheckYamlConfig[Check Cassandra.yaml file configuration.]
Decision_NodesUN{{"Are all nodes UN? <br/>(i.e. Up and Normal)"}}
Decision_LoadValues{{Are load values within 5% variance?}}
Decision_ReachEachOther{{Can nodes reach each other?}}
Decision_YamlWellConvigured{{Is the Cassandra.yaml file well configured?}}
Decision_ProblemsPersist{{Do problems persist?}}
Solution_CheckNetworkIssues[Check network issues.]
Solution_RestartCassandra[Restart Cassandra.]
START --> Action_NodetoolStatus --> Decision_NodesUN
Decision_NodesUN --> |YES| Decision_LoadValues
Decision_NodesUN --> |NO| Decision_ReachEachOther
Decision_LoadValues --> |YES| Action_CassandraLogsExceptions --> ActionClick_GarbageCollection
Decision_LoadValues --> |NO| ActionClick_RunRepair --> ActionClick_GarbageCollection
ActionClick_GarbageCollection --> Solution_RestartCassandra
Decision_ReachEachOther --> |YES| Decision_YamlWellConvigured
Decision_ReachEachOther --> |NO| Solution_CheckNetworkIssues --> Solution_RestartCassandra
Decision_YamlWellConvigured --> |YES| ActionClick_GarbageCollection
Decision_YamlWellConvigured --> |NO| ActionClick_CheckYamlConfig --> Solution_RestartCassandra
Solution_RestartCassandra --> Decision_ProblemsPersist
Decision_ProblemsPersist --> |YES| HOME
Decision_ProblemsPersist --> |NO| END
%% -------------------------------------------------------------------------
%% all blocks terminating at a common End?
%% -------------------------------------------------------------------------
%% -------------------------------------------------------------------------
%% Define hyperlinks %%
%% -------------------------------------------------------------------------
click HOME "https://community.dataminer.services/troubleshooting-cassandra/"
click ActionClick_GarbageCollection "/troubleshooting-cassandra-nodetool-status/#GarbageCollection"
click ActionClick_RunRepair "/troubleshooting-cassandra-nodetool-status/#RunRepair"
click ActionClick_CheckYamlConfig "/troubleshooting-cassandra/#yaml"
%% -------------------------------------------------------------------------
%% Apply styles to blocks
%% -------------------------------------------------------------------------
class Action_NodetoolStatus,Action_CassandraLogsExceptions classAction;
class ActionClick_RunRepair,ActionClick_GarbageCollection,ActionClick_CheckYamlConfig classActionClickable;
class Decision_NodesUN,Decision_LoadValues,Decision_ReachEachOther,Decision_YamlWellConvigured,Decision_ProblemsPersist classDecision;
class HOME classExternalRef;
class Solution_CheckNetworkIssues,Solution_CheckYamlConfig,Solution_RestartCassandra classSolution;
class START,END classTerminal;
Ensuring that all data is replicated
To ensure that all data is replicated, you should run the nodetool repair command.
- First, try with:
nodetool repair -full SLDMADB - If this fails, use the following command:
nodetool repair -full -tr SLDMADB >> test.txt
In a new command prompt window, you can monitor a nodetool repair operation with two nodetool commands:
compactionstatsnetstats
Review the repair history in DevCenter with the following query:
select * from repair_history where keyspace_name ='SLDMADB' and columnfamily_name = '[TABLE_NAME]' order by id desc;
This will return information on the latest repair for a particular SLDMADB table, as illustrated in the image below.
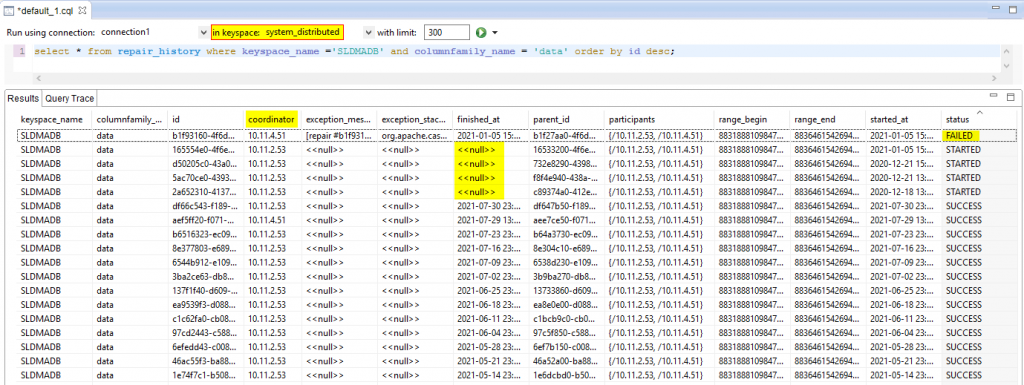
- The "coordinator" column indicates which node initiated the repair.
- The "finished_at" column shows a timestamp that can help you trace problems. If the "status" column mentions "FAILED", as illustrated above, check the logging of both Cassandra nodes for exceptions, while referring to the "finished_at" column for timestamp information.
- A <<null>> value in the "finished_at" column indicates no time was retrieved (e.g. still busy or restarted during that time).
- For a multi-node system, it is important that there are some successful repairs.
Checking Cassandra logging for long or frequent garbage collection pauses
These will cause Cassandra to be unable to write, as this operation takes the Cassandra node offline.
Check if you can find similar GC info events as in the following example in your system.log file:
INFO [ScheduledTasks:1] 2013-03-07 18:44:46,795 GCInspector.java (line 122) GC for ConcurrentMarkSweep: 1835 ms for 3 collections, 2606015656 used; max is 10611589120
INFO [ScheduledTasks:1] 2013-03-07 19:45:08,029 GCInspector.java (line 122) GC for ParNew: 9866 ms for 8 collections, 2910124308 used; max is 6358564864Causes of garbage collection pauses include:
- Recent application changes: If the problem is recent, check if any applications changes have recently occurred.
- Excessive tombstone activity: This is often caused by heavy delete workloads.
- Large row or batch updates: To resolve this, reduce the size of the individual write to less than 1 Mb.
- Extremely wide rows: This manifests as problems in repairs, selects, caching, and elsewhere.